



More on Technology

Nicolas Tresegnie
3 years ago
Launching 10 SaaS applications in 100 days

Apocodes helps entrepreneurs create SaaS products without writing code. This post introduces micro-SaaS and outlines its basic strategy.
Strategy
Vision and strategy differ when starting a startup.
The company's long-term future state is outlined in the vision. It establishes the overarching objectives the organization aims to achieve while also justifying its existence. The company's future is outlined in the vision.
The strategy consists of a collection of short- to mid-term objectives, the accomplishment of which will move the business closer to its vision. The company gets there through its strategy.
The vision should be stable, but the strategy must be adjusted based on customer input, market conditions, or previous experiments.
Begin modestly and aim high.
Be truthful. It's impossible to automate SaaS product creation from scratch. It's like climbing Everest without running a 5K. Physical rules don't prohibit it, but it would be suicide.
Apocodes 5K equivalent? Two options:
(A) Create a feature that includes every setting option conceivable. then query potential clients “Would you choose us to build your SaaS solution if we offered 99 additional features of the same caliber?” After that, decide which major feature to implement next.
(B) Build a few straightforward features with just one or two configuration options. Then query potential clients “Will this suffice to make your product?” What's missing if not? Finally, tweak the final result a bit before starting over.
(A) is an all-or-nothing approach. It's like training your left arm to climb Mount Everest. My right foot is next.
(B) is a better method because it's iterative and provides value to customers throughout.
Focus on a small market sector, meet its needs, and expand gradually. Micro-SaaS is Apocode's first market.
What is micro-SaaS.
Micro-SaaS enterprises have these characteristics:
A limited range: They address a specific problem with a small number of features.
A small group of one to five individuals.
Low external funding: The majority of micro-SaaS companies have Total Addressable Markets (TAM) under $100 million. Investors find them unattractive as a result. As a result, the majority of micro-SaaS companies are self-funded or bootstrapped.
Low competition: Because they solve problems that larger firms would rather not spend time on, micro-SaaS enterprises have little rivalry.
Low upkeep: Because of their simplicity, they require little care.
Huge profitability: Because providing more clients incurs such a small incremental cost, high profit margins are possible.
Micro-SaaS enterprises created with no-code are Apocode's ideal first market niche.
We'll create our own micro-SaaS solutions to better understand their needs. Although not required, we believe this will improve community discussions.
The challenge
In 100 days (September 12–December 20, 2022), we plan to build 10 micro-SaaS enterprises using Apocode.
They will be:
Self-serve: Customers will be able to use the entire product experience without our manual assistance.
Real: They'll deal with actual issues. They won't be isolated proofs of concept because we'll keep up with them after the challenge.
Both free and paid options: including a free plan and a free trial period. Although financial success would be a good result, the challenge's stated objective is not financial success.
This will let us design Apocodes features, showcase them, and talk to customers.
(Edit: The first micro-SaaS was launched!)
Follow along
If you want to follow the story of Apocode or our progress in this challenge, you can subscribe here.
If you are interested in using Apocode, sign up here.
If you want to provide feedback, discuss the idea further or get involved, email me at nicolas.tresegnie@gmail.com
Colin Faife
3 years ago
The brand-new USB Rubber Ducky is much riskier than before.
The brand-new USB Rubber Ducky is much riskier than before.

With its own programming language, the well-liked hacking tool may now pwn you.
With a vengeance, the USB Rubber Ducky is back.
This year's Def Con hacking conference saw the release of a new version of the well-liked hacking tool, and its author, Darren Kitchen, was on hand to explain it. We put a few of the new features to the test and discovered that the most recent version is riskier than ever.
WHAT IS IT?
The USB Rubber Ducky seems to the untrained eye to be an ordinary USB flash drive. However, when you connect it to a computer, the computer recognizes it as a USB keyboard and will accept keystroke commands from the device exactly like a person would type them in.
Kitchen explained to me, "It takes use of the trust model built in, where computers have been taught to trust a human, in that anything it types is trusted to the same degree as the user is trusted. And a computer is aware that clicks and keystrokes are how people generally connect with it.

Over ten years ago, the first Rubber Ducky was published, quickly becoming a hacker favorite (it was even featured in a Mr. Robot scene). Since then, there have been a number of small upgrades, but the most recent Rubber Ducky takes a giant step ahead with a number of new features that significantly increase its flexibility and capability.
WHERE IS ITS USE?
The options are nearly unlimited with the proper strategy.
The Rubber Ducky has already been used to launch attacks including making a phony Windows pop-up window to collect a user's login information or tricking Chrome into sending all saved passwords to an attacker's web server. However, these attacks lacked the adaptability to operate across platforms and had to be specifically designed for particular operating systems and software versions.

The nuances of DuckyScript 3.0 are described in a new manual.
The most recent Rubber Ducky seeks to get around these restrictions. The DuckyScript programming language, which is used to construct the commands that the Rubber Ducky will enter into a target machine, receives a significant improvement with it. DuckyScript 3.0 is a feature-rich language that allows users to write functions, store variables, and apply logic flow controls, in contrast to earlier versions that were primarily limited to scripting keystroke sequences (i.e., if this... then that).
This implies that, for instance, the new Ducky can check to see if it is hooked into a Windows or Mac computer and then conditionally run code specific to each one, or it can disable itself if it has been attached to the incorrect target. In order to provide a more human effect, it can also generate pseudorandom numbers and utilize them to add a configurable delay between keystrokes.
The ability to steal data from a target computer by encoding it in binary code and transferring it through the signals intended to instruct a keyboard when the CapsLock or NumLock LEDs should light up is perhaps its most astounding feature. By using this technique, a hacker may plug it in for a brief period of time, excuse themselves by saying, "Sorry, I think that USB drive is faulty," and then take it away with all the credentials stored on it.
HOW SERIOUS IS THE RISK?
In other words, it may be a significant one, but because physical device access is required, the majority of people aren't at risk of being a target.
The 500 or so new Rubber Duckies that Hak5 brought to Def Con, according to Kitchen, were his company's most popular item at the convention, and they were all gone on the first day. It's safe to suppose that hundreds of hackers already possess one, and demand is likely to persist for some time.
Additionally, it has an online development toolkit that can be used to create attack payloads, compile them, and then load them onto the target device. A "payload hub" part of the website makes it simple for hackers to share what they've generated, and the Hak5 Discord is also busy with conversation and helpful advice. This makes it simple for users of the product to connect with a larger community.
It's too expensive for most individuals to distribute in volume, so unless your favorite cafe is renowned for being a hangout among vulnerable targets, it's doubtful that someone will leave a few of them there. To that end, if you intend to plug in a USB device that you discovered outside in a public area, pause to consider your decision.
WOULD IT WORK FOR ME?
Although the device is quite straightforward to use, there are a few things that could cause you trouble if you have no prior expertise writing or debugging code. For a while, during testing on a Mac, I was unable to get the Ducky to press the F4 key to activate the launchpad, but after forcing it to identify itself using an alternative Apple keyboard device ID, the problem was resolved.
From there, I was able to create a script that, when the Ducky was plugged in, would instantly run Chrome, open a new browser tab, and then immediately close it once more without requiring any action from the laptop user. Not bad for only a few hours of testing, and something that could be readily changed to perform duties other than reading technology news.

Liz Martin
3 years ago
A Search Engine From Apple?

Apple's search engine has long been rumored. Recent Google developments may confirm the rumor. Is Apple about to become Google's biggest rival?
Here's a video:
People noted Apple's changes in 2020. AppleBot, a web crawler that downloads and caches Internet content, was more active than in the last five years.
Apple hired search engine developers, including ex-Googlers, such as John Giannandrea, Google's former search chief.
Apple also changed the way iPhones search. With iOS 14, Apple's search results arrived before Google's.
These facts fueled rumors that Apple was developing a search engine.
Apple and Google Have a Contract
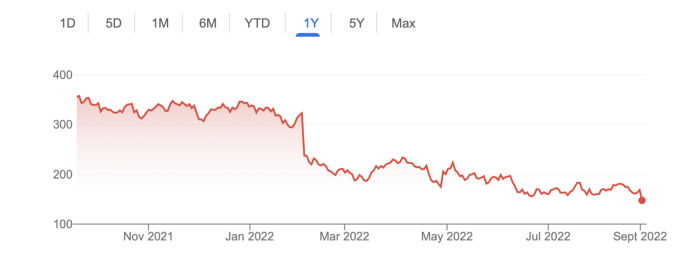
Many skeptics said Apple couldn't compete with Google. This didn't affect the company's competitiveness.
Apple is the only business with the resources and scale to be a Google rival, with 1.8 billion active devices and a $2 trillion market cap.
Still, people doubted that due to a license deal. Google pays Apple $8 to $12 billion annually to be the default iPhone and iPad search engine.
Apple can't build an independent search product under this arrangement.
Why would Apple enter search if it's being paid to stay out?
Ironically, this partnership has many people believing Apple is getting into search.
A New Default Search Engine May Be Needed
Google was sued for antitrust in 2020. It is accused of anticompetitive and exclusionary behavior. Justice wants to end Google's monopoly.
Authorities could restrict Apple and Google's licensing deal due to its likely effect on market competitiveness. Hence Apple needs a new default search engine.
Apple Already Has a Search Engine
The company already has a search engine, Spotlight.

Since 2004, Spotlight has aired. It was developed to help users find photos, documents, apps, music, and system preferences.
Apple's search engine could do more than organize files, texts, and apps.
Spotlight Search was updated in 2014 with iOS 8. Web, App Store, and iTunes searches became available. You could find nearby places, movie showtimes, and news.
This search engine has subsequently been updated and improved. Spotlight added rich search results last year.
If you search for a TV show, movie, or song, photos and carousels will appear at the top of the page.
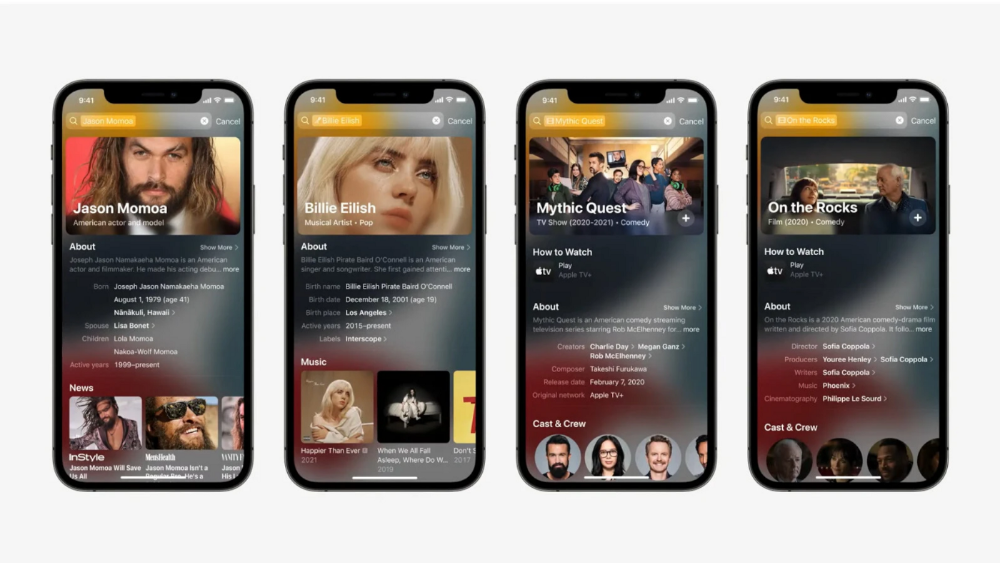
This resembles Google's rich search results.
When Will the Apple Search Engine Be Available?
When will Apple's search launch? Robert Scoble says it's near.
Scoble tweeted a number of hints before this year's Worldwide Developer Conference.
Scoble bases his prediction on insider information and deductive reasoning. January 2023 is expected.
Will you use Apple's search engine?
You might also like

CNET
4 years ago
How a $300K Bored Ape Yacht Club NFT was accidentally sold for $3K
The Bored Ape Yacht Club is one of the most prestigious NFT collections in the world. A collection of 10,000 NFTs, each depicting an ape with different traits and visual attributes, Jimmy Fallon, Steph Curry and Post Malone are among their star-studded owners. Right now the price of entry is 52 ether, or $210,000.
Which is why it's so painful to see that someone accidentally sold their Bored Ape NFT for $3,066.
Unusual trades are often a sign of funny business, as in the case of the person who spent $530 million to buy an NFT from themselves. In Saturday's case, the cause was a simple, devastating "fat-finger error." That's when people make a trade online for the wrong thing, or for the wrong amount. Here the owner, real name Max or username maxnaut, meant to list his Bored Ape for 75 ether, or around $300,000. Instead he accidentally listed it for 0.75. One hundredth the intended price.
It was bought instantaneously. The buyer paid an extra $34,000 to speed up the transaction, ensuring no one could snap it up before them. The Bored Ape was then promptly listed for $248,000. The transaction appears to have been done by a bot, which can be coded to immediately buy NFTs listed below a certain price on behalf of their owners in order to take advantage of these exact situations.
"How'd it happen? A lapse of concentration I guess," Max told me. "I list a lot of items every day and just wasn't paying attention properly. I instantly saw the error as my finger clicked the mouse but a bot sent a transaction with over 8 eth [$34,000] of gas fees so it was instantly sniped before I could click cancel, and just like that, $250k was gone."
"And here within the beauty of the Blockchain you can see that it is both honest and unforgiving," he added.
Fat finger trades happen sporadically in traditional finance -- like the Japanese trader who almost bought 57% of Toyota's stock in 2014 -- but most financial institutions will stop those transactions if alerted quickly enough. Since cryptocurrency and NFTs are designed to be decentralized, you essentially have to rely on the goodwill of the buyer to reverse the transaction.
Fat finger errors in cryptocurrency trades have made many a headline over the past few years. Back in 2019, the company behind Tether, a cryptocurrency pegged to the US dollar, nearly doubled its own coin supply when it accidentally created $5 billion-worth of new coins. In March, BlockFi meant to send 700 Gemini Dollars to a set of customers, worth roughly $1 each, but mistakenly sent out millions of dollars worth of bitcoin instead. Last month a company erroneously paid a $24 million fee on a $100,000 transaction.
Similar incidents are increasingly being seen in NFTs, now that many collections have accumulated in market value over the past year. Last month someone tried selling a CryptoPunk NFT for $19 million, but accidentally listed it for $19,000 instead. Back in August, someone fat finger listed their Bored Ape for $26,000, an error that someone else immediately capitalized on. The original owner offered $50,000 to the buyer to return the Bored Ape -- but instead the opportunistic buyer sold it for the then-market price of $150,000.
"The industry is so new, bad things are going to happen whether it's your fault or the tech," Max said. "Once you no longer have control of the outcome, forget and move on."
The Bored Ape Yacht Club launched back in April 2021, with 10,000 NFTs being sold for 0.08 ether each -- about $190 at the time. While NFTs are often associated with individual digital art pieces, collections like the Bored Ape Yacht Club, which allow owners to flaunt their NFTs by using them as profile pictures on social media, are becoming increasingly prevalent. The Bored Ape Yacht Club has since become the second biggest NFT collection in the world, second only to CryptoPunks, which launched in 2017 and is considered the "original" NFT collection.

Michael Salim
3 years ago
300 Signups, 1 Landing Page, 0 Products
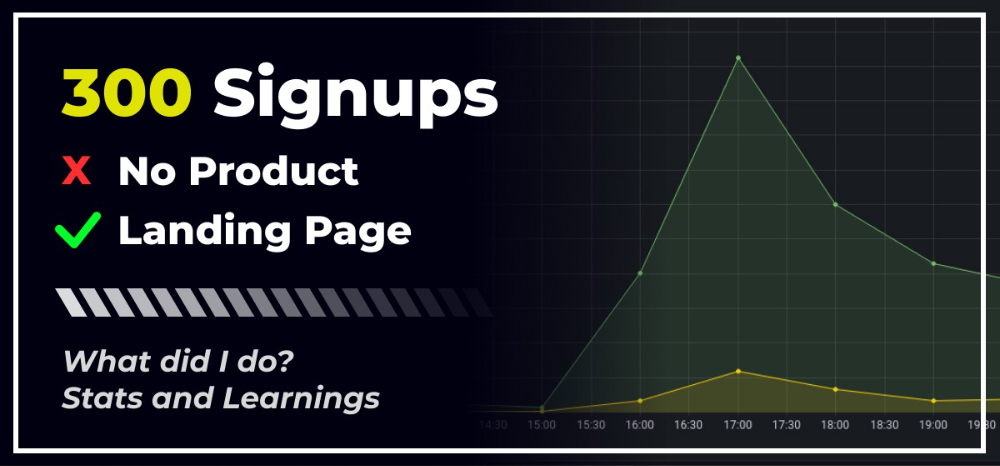
I placed a link on HackerNews and got 300 signups in a week. This post explains what happened.
Product Concept
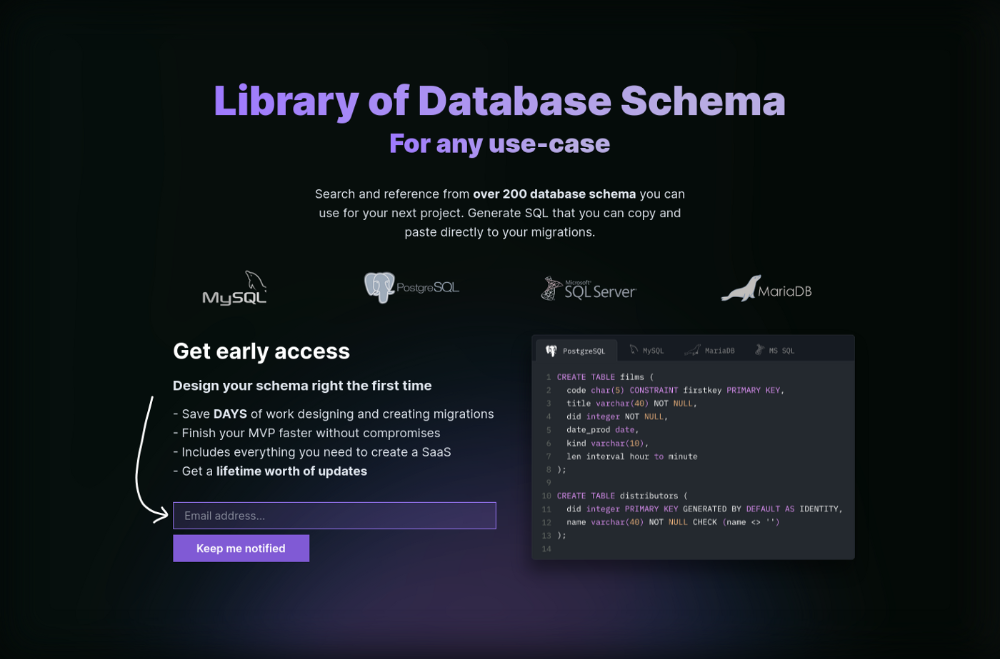
The product is DbSchemaLibrary. A library of Database Schema.
I'm not sure where this idea originated from. Very fast. Build fast, fail fast, test many ideas, and one will be a hit. I tried it. Let's try it anyway, even though it'll probably fail. I finished The Lean Startup book and wanted to use it.
Database job bores me. Important! I get drowsy working on it. Someone must do it. I remember this happening once. I needed examples at the time. Something similar to Recall (my other project) that I can copy — or at least use as a reference.
Frequently googled. Many tabs open. The results were useless. I raised my hand and agreed to construct the database myself.
It resurfaced. I decided to do something.
Due Diligence
Lean Startup emphasizes validated learning. Everything the startup does should result in learning. I may build something nobody wants otherwise. That's what happened to Recall.
So, I wrote a business plan document. This happens before I code. What am I solving? What is my proposed solution? What is the leap of faith between the problem and solution? Who would be my target audience?
My note:

In my previous project, I did the opposite!
I wrote my expectations after reading the book's advice.
“Failure is a prerequisite to learning. The problem with the notion of shipping a product and then seeing what happens is that you are guaranteed to succeed — at seeing what happens.” — The Lean Startup book
These are successful metrics. If I don't reach them, I'll drop the idea and try another. I didn't understand numbers then. Below are guesses. But it’s a start!

I then wrote the project's What and Why. I'll use this everywhere. Before, I wrote a different pitch each time. I thought certain words would be better. I felt the audience might want something unusual.
Occasionally, this works. I'm unsure if it's a good idea. No stats, just my writing-time opinion. Writing every time is time-consuming and sometimes hazardous. Having a copy saved me duplication.
I can measure and learn from performance.

Last, I identified communities that might demand the product. This became an exercise in creativity.
The MVP
So now it’s time to build.
A MVP can test my assumptions. Business may learn from it. Not low-quality. We should learn from the tiniest thing.
I like the example of how Dropbox did theirs. They assumed that if the product works, people will utilize it. How can this be tested without a quality product? They made a movie demonstrating the software's functionality. Who knows how much functionality existed?
So I tested my biggest assumption. Users want schema references. How can I test if users want to reference another schema? I'd love this. Recall taught me that wanting something doesn't mean others do.
I made an email-collection landing page. Describe it briefly. Reference library. Each email sender wants a reference. They're interested in the product. Few other reasons exist.
Header and footer were skipped. No name or logo. DbSchemaLibrary is a name I thought of after the fact. 5-minute logo. I expected a flop. Recall has no users after months of labor. What could happen to a 2-day project?
I didn't compromise learning validation. How many visitors sign up? To draw a conclusion, I must track these results.
Posting Time
Now that the job is done, gauge interest. The next morning, I posted on all my channels. I didn't want to be spammy, therefore it required more time.
I made sure each channel had at least one fan of this product. I also answer people's inquiries in the channel.
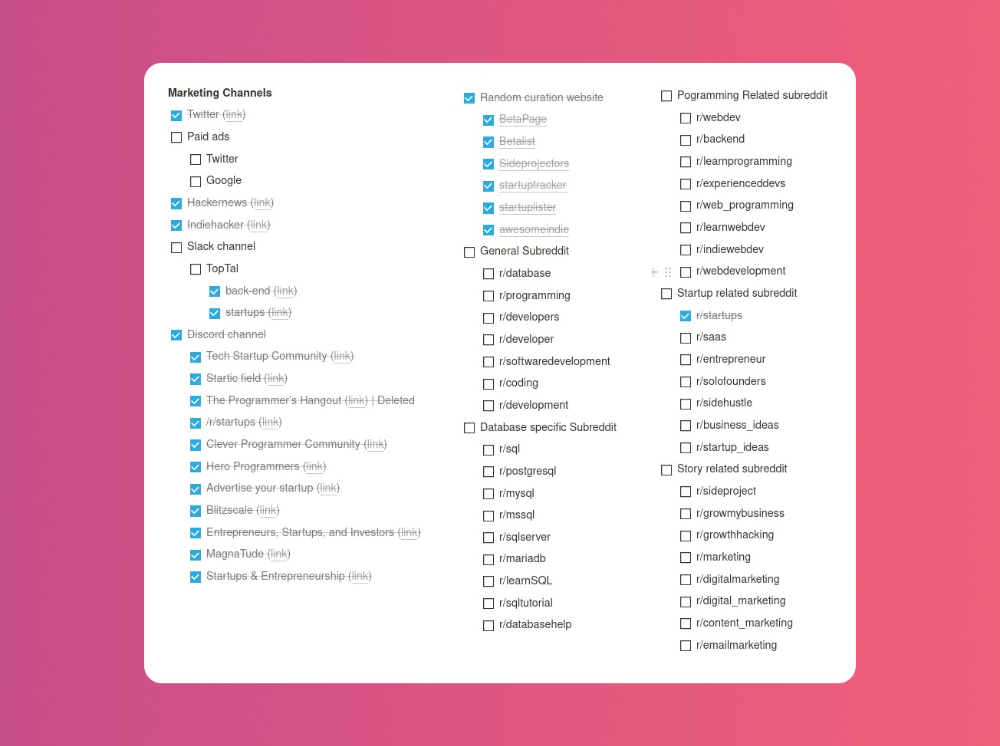
My list stinks. Several channels wouldn't work. The product's target market isn't there. Posting there would waste our time. This taught me to create marketing channels depending on my persona.
Statistics! What actually happened
My favorite part! 23 channels received the link.
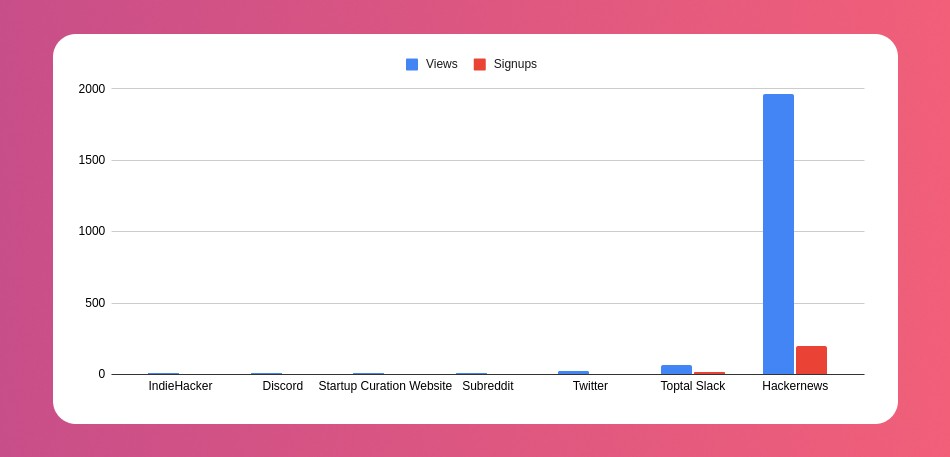
I stopped posting to Discord despite its high conversion rate. I eliminated some channels because they didn't fit. According to the numbers, some users like it. Most users think it's spam.
I was skeptical. And 12 people viewed it.
I didn't expect much attention on a startup subreddit. I'll likely examine Reddit further in the future. As I have enough info, I didn't post much. Time for the next validated learning
No comment. The post had few views, therefore the numbers are low.
The targeted people come next.
I'm a Toptal freelancer. There's a member-only Slack channel. Most people can't use this marketing channel, but you should! It's not as spectacular as discord's 27% conversion rate. But I think the users here are better.
I don’t really have a following anywhere so this isn’t something I can leverage.
The best yet. 10% is converted. With more data, I expect to attain a 10% conversion rate from other channels. Stable number.
This number required some work. Did you know that people use many different clients to read HN?
Unknowns
Untrackable views and signups abound. 1136 views and 135 signups are untraceable. It's 11%. I bet much of that came from Hackernews.
Overall Statistics
The 7-day signup-to-visit ratio was 17%. (Hourly data points)
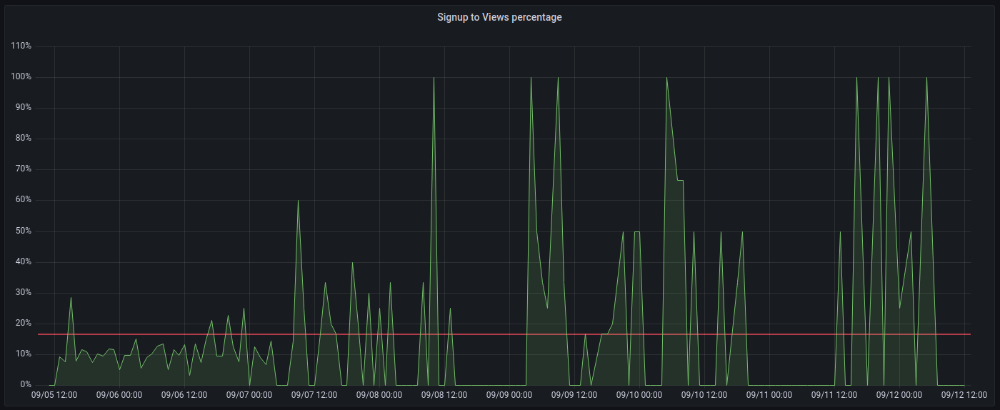
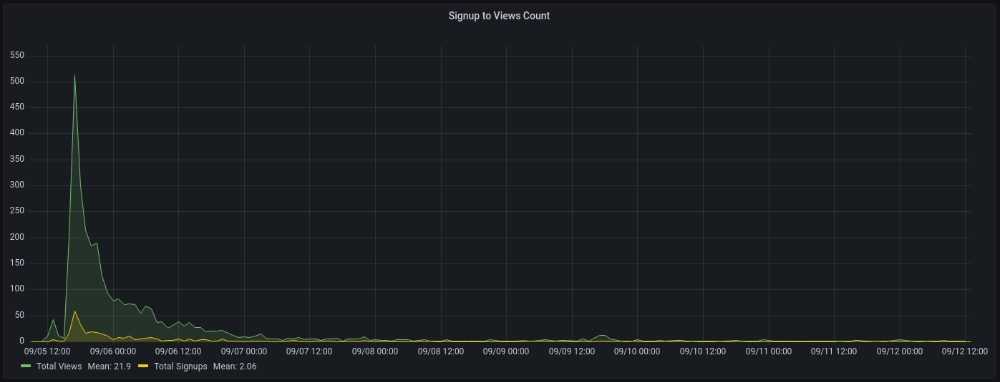
First-day percentages were lower, which is noteworthy. Initially, it was little above 10%. The HN post started getting views then.
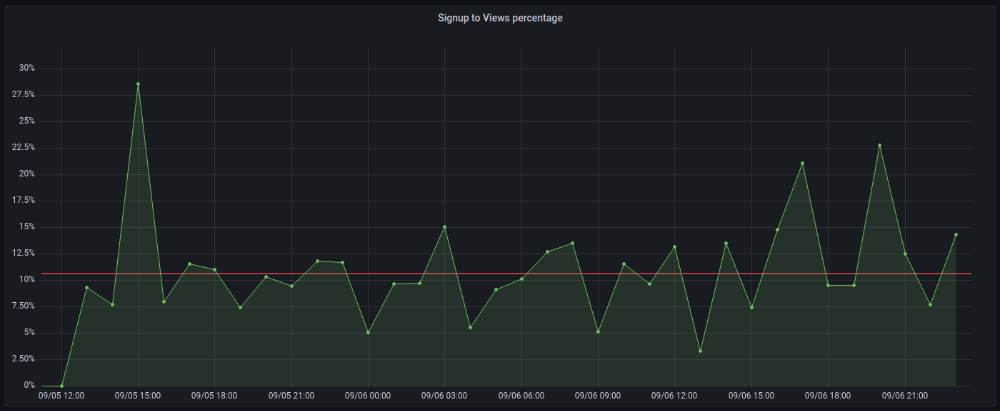
When traffic drops, the number reaches just around 20%. More individuals are interested in the connection. hn.algolia.com sent 2 visitors. This means people are searching and finding my post.
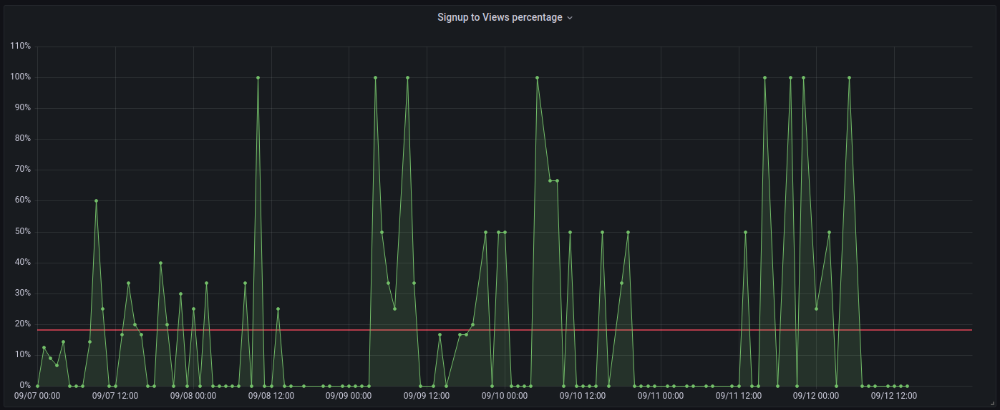
Interesting discoveries
1. HN post struggled till the US woke up.
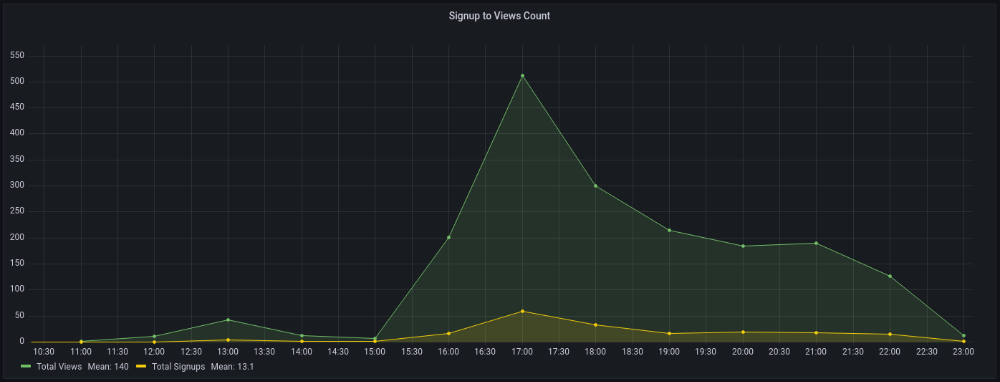
11am UTC. After an hour, it lost popularity. It seemed over. 7 signups converted 13%. Not amazing, but I would've thought ahead.
After 4pm UTC, traffic grew again. 4pm UTC is 9am PDT. US awakened. 10am PDT saw 512 views.
2. The product was highlighted in a newsletter.
I found Revue references when gathering data. Newsletter platform. Someone posted the newsletter link. 37 views and 3 registrations.
3. HN numbers are extremely reliable
I don't have a time-lapse graph (yet). The statistics were constant all day.
2717 views later 272 new users, or 10.1%
With 293 signups at 2856 views, 10.25%
At 306 signups at 2965 views, 10.32%
Learnings
1. My initial estimations were wildly inaccurate
I wrote 30% conversion. Reading some articles, looks like 10% is a good number to aim for.
2. Paying attention to what matters rather than vain metrics
The Lean Startup discourages vanity metrics. Feel-good metrics that don't measure growth or traction. Considering the proportion instead of the total visitors made me realize there was something here.
What’s next?
There are lots of work to do. Data aggregation, display, website development, marketing, legal issues. Fun! It's satisfying to solve an issue rather than investigate its cause.
In the meantime, I’ve already written the first project update in another post. Continue reading it if you’d like to know more about the project itself! Shifting from Quantity to Quality — DbSchemaLibrary

Rajesh Gupta
3 years ago
Why Is It So Difficult to Give Up Smoking?

I started smoking in 2002 at IIT BHU. Most of us thought it was enjoyable at first. I didn't realize the cost later.
In 2005, during my final semester, I lost my father. Suddenly, I felt more accountable for my mother and myself.
I quit before starting my first job in Bangalore. I didn't see any smoking friends in my hometown for 2 months before moving to Bangalore.
For the next 5-6 years, I had no regimen and smoked only when drinking.
Due to personal concerns, I started smoking again after my 2011 marriage. Now smoking was a constant guilty pleasure.
I smoked 3-4 cigarettes a day, but never in front of my family or on weekends. I used to excuse this with pride! First office ritual: smoking. Even with guilt, I couldn't stop this time because of personal concerns.
After 8-9 years, in mid 2019, a personal development program solved all my problems. I felt complete in myself. After this, I just needed one cigarette each day.
The hardest thing was leaving this final cigarette behind, even though I didn't want it.
James Clear's Atomic Habits was published last year. I'd only read 2-3 non-tech books before reading this one in August 2021. I knew everything but couldn't use it.
In April 2022, I realized the compounding effect of a bad habit thanks to my subconscious mind. 1 cigarette per day (excluding weekends) equals 240 = 24 packs per year, which is a lot. No matter how much I did, it felt negative.
Then I applied the 2nd principle of this book, identifying the trigger. I tried to identify all the major triggers of smoking. I found social drinking is one of them & If I am able to control it during that time, I can easily control it in other situations as well. Going further whenever I drank, I was pre-determined to ignore the craving at any cost. Believe me, it was very hard initially but gradually this craving started fading away even with drinks.
I've been smoke-free for 3 months. Now I know a bad habit's effects. After realizing the power of habits, I'm developing other good habits which I ignored all my life.