





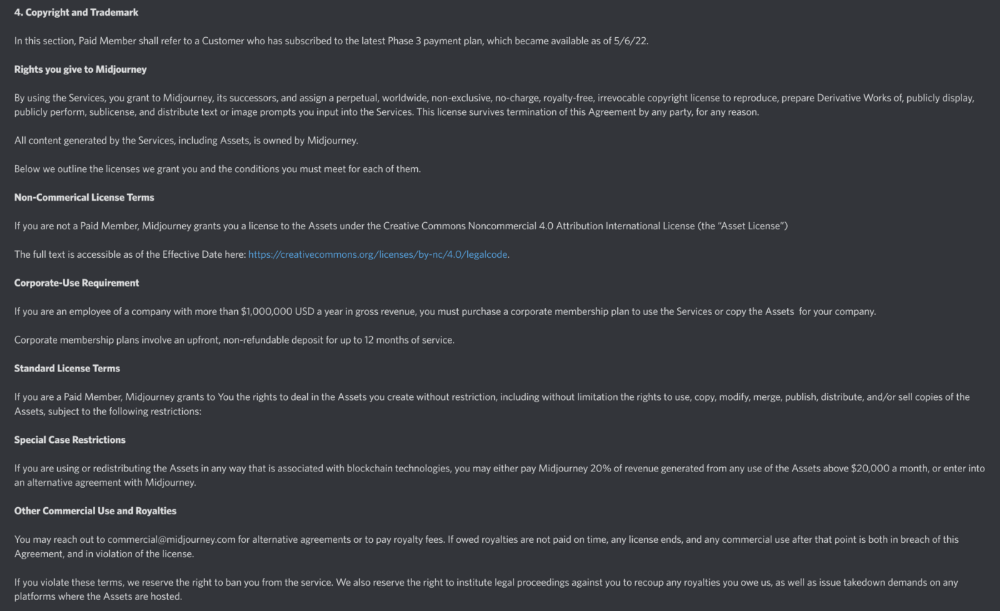

More on NFTs & Art

Abhimanyu Bhargava
3 years ago
VeeFriends Series 2: The Biggest NFT Opportunity Ever
VeeFriends is one NFT project I'm sure will last.

I believe in blockchain technology and JPEGs, aka NFTs. NFTs aren't JPEGs. It's not as it seems.
Gary Vaynerchuk is leading the pack with his new NFT project VeeFriends, I wrote a year ago. I was spot-on. It's the most innovative project I've seen.
Since its minting in May 2021, it has given its holders enormous value, most notably the first edition of VeeCon, a multi-day superconference featuring iconic and emerging leaders in NFTs and Popular Culture. First-of-its-kind NFT-ticketed Web3 conference to build friendships, share ideas, and learn together.
VeeFriends holders got free VeeCon NFT tickets. Attendees heard iconic keynote speeches, innovative talks, panels, and Q&A sessions.
It was a unique conference that most of us, including me, are looking forward to in 2023. The lineup was epic, and it allowed many to network in new ways. Really memorable learning. Here are a couple of gratitude posts from the attendees.
VeeFriends Series 2
This article explains VeeFriends if you're still confused.
GaryVee's hand-drawn doodles have evolved into wonderful characters. The characters' poses and backgrounds bring the VeeFriends IP to life.

Yes, this is the second edition of VeeFriends, and at current prices, it's one of the best NFT opportunities in years. If you have the funds and risk appetite to invest in NFTs, VeeFriends Series 2 is worth every penny. Even if you can't invest, learn from their journey.
1. Art Is the Start
Many critics say VeeFriends artwork is below average and not by GaryVee. Art is often the key to future success.
Let's look at one of the first Mickey Mouse drawings. No one would have guessed that this would become one of the most beloved animated short film characters. In Walt Before Mickey, Walt Disney's original mouse Mortimer was less refined.
First came a mouse...

These sketches evolved into Steamboat Willie, Disney's first animated short film.

Fred Moore redesigned the character artwork into what we saw in cartoons as kids. Mickey Mouse's history is here.

Looking at how different cartoon characters have evolved and gained popularity over decades, I believe Series 2 characters like Self-Aware Hare, Kind Kudu, and Patient Pig can do the same.

GaryVee captures this journey on the blockchain and lets early supporters become part of history. Time will tell if it rivals Disney, Pokemon, or Star Wars. Gary has been vocal about this vision.
2. VeeFriends is Intellectual Property for the Coming Generations
Most of us grew up watching cartoons, playing with toys, cards, and video games. Our interactions with fictional characters and the stories we hear shape us.
GaryVee is slowly curating an experience for the next generation with animated videos, card games, merchandise, toys, and more.
VeeFriends UNO, a collaboration with Mattel Creations, features 17 VeeFriends characters.
VeeFriends and Zerocool recently released Trading Cards featuring all 268 Series 1 characters and 15 new ones. Another way to build VeeFriends' collectibles brand.

At Veecon, all the characters were collectible toys. Something will soon emerge.
Kids and adults alike enjoy the YouTube channel's animated shorts and VeeFriends Tunes. Here's a song by the holder's Optimistic Otter-loving daughter.
This VeeFriends story is only the beginning. I'm looking forward to animated short film series, coloring books, streetwear, candy, toys, physical collectibles, and other forms of VeeFriends IP.
3. Veefriends will always provide utilities
Smart contracts can be updated at any time and authenticated on a ledger.
VeeFriends Series 2 gives no promise of any utility whatsoever. GaryVee released no project roadmap. In the first few months after launch, many owners of specific characters or scenes received utilities.
Every benefit or perk you receive helps promote the VeeFriends brand.
Recent partnerships are listed below.
MaryRuth's Multivitamin Gummies
Productive Puffin holders from VeeFriends x Primitive
Pickleball Scene & Clown Holders Only

Pickleball & Competitive Clown Exclusive experience, anteater multivitamin gummies, and Puffin x Primitive merch
Considering the price of NFTs, it may not seem like much. It's just the beginning; you never know what the future holds. No other NFT project offers such diverse, ongoing benefits.
4. Garyvee's team is ready
Gary Vaynerchuk's team and record are undisputed. He's a serial entrepreneur and the Chairman & CEO of VaynerX, which includes VaynerMedia, VaynerCommerce, One37pm, and The Sasha Group.
Gary founded VaynerSports, Resy, and Empathy Wines. He's a Candy Digital Board Member, VCR Group Co-Founder, ArtOfficial Co-Founder, and VeeFriends Creator & CEO. Gary was recently named one of Fortune's Top 50 NFT Influencers.

Gary Vayenerchuk aka GaryVee
Gary documents his daily life as a CEO on social media, which has 34 million followers and 272 million monthly views. GaryVee Audio Experience is a top podcast. He's a five-time New York Times best-seller and sought-after speaker.
Gary can observe consumer behavior to predict trends. He understood these trends early and pioneered them.
1997 — Realized e-potential commerce's and started winelibrary.com. In five years, he grew his father's wine business from $3M to $60M.
2006 — Realized content marketing's potential and started Wine Library on YouTube. TV
2009 — Estimated social media's potential (Web2) and invested in Facebook, Twitter, and Tumblr.
2014: Ethereum and Bitcoin investments
2021 — Believed in NFTs and Web3 enough to launch VeeFriends
GaryVee isn't all of VeeFriends. Andy Krainak, Dave DeRosa, Adam Ripps, Tyler Dowdle, and others work tirelessly to make VeeFriends a success.
GaryVee has said he'll let other businesses fail but not VeeFriends. We're just beginning his 40-year vision.
I have more confidence than ever in a company with a strong foundation and team.
5. Humans die, but characters live forever
What if GaryVee dies or can't work?
A writer's books can immortalize them. As long as their books exist, their words are immortal. Socrates, Hemingway, Aristotle, Twain, Fitzgerald, and others have become immortal.
Everyone knows Vincent Van Gogh's The Starry Night.
We all love reading and watching Peter Parker, Thor, or Jessica Jones. Their behavior inspires us. Stan Lee's message and stories live on despite his death.
GaryVee represents VeeFriends. Creating characters to communicate ensures that the message reaches even those who don't listen.
Gary wants his values and messages to be omnipresent in 268 characters. Messengers die, but their messages live on.
Gary envisions VeeFriends creating timeless stories and experiences. Ten years from now, maybe every kid will sing Patient Pig.
6. I love the intent.
Gary planned to create Workplace Warriors three years ago when he began designing Patient Panda, Accountable Ant, and Empathy elephant. The project stalled. When NFTs came along, he knew.
Gary wanted to create characters with traits he values, such as accountability, empathy, patience, kindness, and self-awareness. He wants future generations to find these traits cool. He hopes one or more of his characters will become pop culture icons.
These emotional skills aren't taught in schools or colleges, but they're crucial for business and life success. I love that someone is teaching this at scale.
In the end, intent matters.
Humans Are Collectors
Buy and collect things to communicate. Since the 1700s. Medieval people formed communities around hidden metals and stones. Many people still collect stamps and coins, and luxury and fashion are multi-trillion dollar industries. We're collectors.
The early 2020s NFTs will be remembered in the future. VeeFriends will define a cultural and technological shift in this era. VeeFriends Series 1 is the original hand-drawn art, but it's expensive. VeeFriends Series 2 is a once-in-a-lifetime opportunity at $1,000.
If you are new to NFTs, check out How to Buy a Non Fungible Token (NFT) For Beginners
This is a non-commercial article. Not financial or legal advice. Information isn't always accurate. Before making important financial decisions, consult a pro or do your own research.
This post is a summary. Read the full article here

Yogita Khatri
3 years ago
Moonbirds NFT sells for $1 million in first week
On Saturday, Moonbird #2642, one of the collection's rarest NFTs, sold for a record 350 ETH (over $1 million) on OpenSea.
The Sandbox, a blockchain-based gaming company based in Hong Kong, bought the piece. The seller, "oscuranft" on OpenSea, made around $600,000 after buying the NFT for 100 ETH a week ago.
Owl avatars
Moonbirds is a 10,000 owl NFT collection. It is one of the quickest collections to achieve bluechip status. Proof, a media startup founded by renowned VC Kevin Rose, launched Moonbirds on April 16.
Rose is currently a partner at True Ventures, a technology-focused VC firm. He was a Google Ventures general partner and has 1.5 million Twitter followers.
Rose has an NFT podcast on Proof. It follows Proof Collective, a group of 1,000 NFT collectors and artists, including Beeple, who hold a Proof Collective NFT and receive special benefits.
These include early access to the Proof podcast and in-person events.
According to the Moonbirds website, they are "the official Proof PFP" (picture for proof).
Moonbirds NFTs sold nearly $360 million in just over a week, according to The Block Research and Dune Analytics. Its top ten sales range from $397,000 to $1 million.
In the current market, Moonbirds are worth 33.3 ETH. Each NFT is 2.5 ETH. Holders have gained over 12 times in just over a week.
Why was it so popular?
The Block Research's NFT analyst, Thomas Bialek, attributes Moonbirds' rapid rise to Rose's backing, the success of his previous Proof Collective project, and collectors' preference for proven NFT projects.
Proof Collective NFT holders have made huge gains. These NFTs were sold in a Dutch auction last December for 5 ETH each. According to OpenSea, the current floor price is 109 ETH.
According to The Block Research, citing Dune Analytics, Proof Collective NFTs have sold over $39 million to date.
Rose has bigger plans for Moonbirds. Moonbirds is introducing "nesting," a non-custodial way for holders to stake NFTs and earn rewards.
Holders of NFTs can earn different levels of status based on how long they keep their NFTs locked up.
"As you achieve different nest status levels, we can offer you different benefits," he said. "We'll have in-person meetups and events, as well as some crazy airdrops planned."
Rose went on to say that Proof is just the start of "a multi-decade journey to build a new media company."

Web3Lunch
3 years ago
An employee of OpenSea might get a 40-year prison sentence for insider trading using NFTs.

The space had better days. Those greenish spikes...oh wow, haven't felt that in ages. Cryptocurrencies and NFTs have lost popularity. Google agrees. Both are declining.
As seen below, crypto interest spiked in May because of the Luna fall. NFT interest is similar to early October last year.
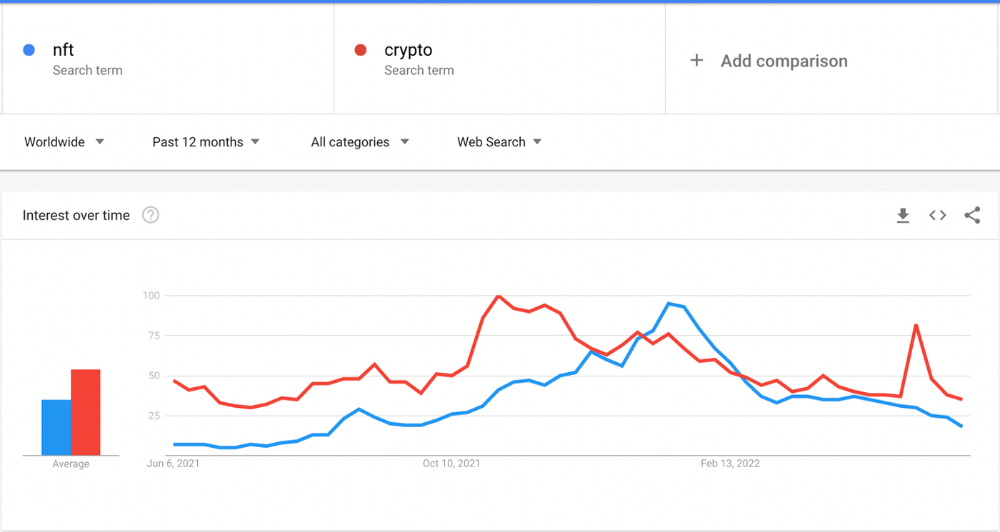
This makes me think NFTs are mostly hype and FOMO. No art or community. I've seen enough initiatives to know that communities stick around if they're profitable. Once it starts falling, they move on to the next project. The space has no long-term investments. Flip everything.
OpenSea trading volume has stayed steady for months. May's volume is 1.8 million ETH ($3.3 billion).
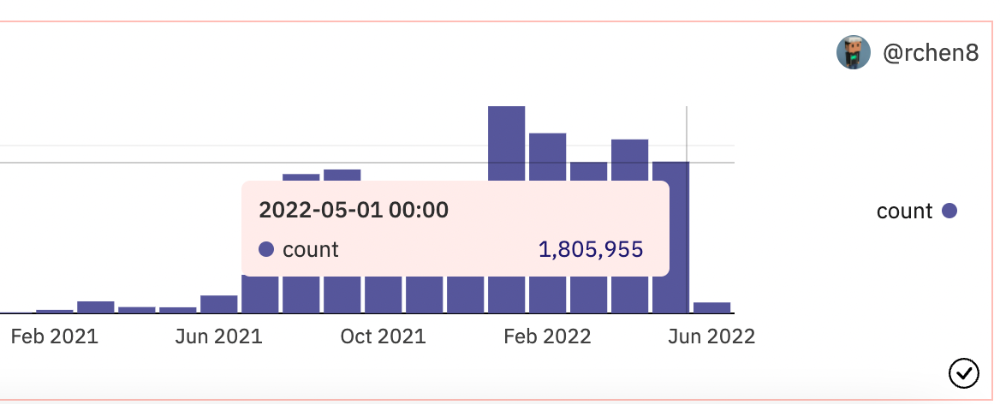
Despite this, I think NFTs and crypto will stick around. In bad markets, builders gain most.
Only 4k developers are active on Ethereum blockchain. It's low. A great chance for the space enthusiasts.
An employee of OpenSea might get a 40-year prison sentence for insider trading using NFTs.
Nathaniel Chastian, an OpenSea employee, traded on insider knowledge. He'll serve 40 years for that.
Here's what happened if you're unfamiliar.
OpenSea is a secondary NFT marketplace. Their homepage featured remarkable drops. Whatever gets featured there, NFT prices will rise 5x.
Chastian was at OpenSea. He chose forthcoming NFTs for OpenSeas' webpage.
Using anonymous digital currency wallets and OpenSea accounts, he would buy NFTs before promoting them on the homepage, showcase them, and then sell them for at least 25 times the price he paid.
From June through September 2021, this happened. Later caught, fired. He's charged with wire fraud and money laundering, each carrying a 20-year maximum penalty.
Although web3 space is all about decentralization, a step like this is welcomed since it restores faith in the area. We hope to see more similar examples soon.
Here's the press release.

Understanding smart contracts
@cantino.eth has a Twitter thread on smart contracts. Must-read. Also, he appears educated about the space, so follow him.

You might also like

The woman
3 years ago
The renowned and highest-paid Google software engineer
His story will inspire you.

“Google search went down for a few hours in 2002; Jeff Dean handled all the queries by hand and checked quality doubled.”- Jeff Dean Facts.
One of many Jeff Dean jokes, but you get the idea.
Google's top six engineers met in a war room in mid-2000. Google's crawling system, which indexed the Web, stopped working. Users could still enter queries, but results were five months old.
Google just signed a deal with Yahoo to power a ten-times-larger search engine. Tension rose. It was crucial. If they failed, the Yahoo agreement would likely fall through, risking bankruptcy for the firm. Their efforts could be lost.
A rangy, tall, energetic thirty-one-year-old man named Jeff dean was among those six brilliant engineers in the makeshift room. He had just left D. E. C. a couple of months ago and started his career in a relatively new firm Google, which was about to change the world. He rolled his chair over his colleague Sanjay and sat right next to him, cajoling his code like a movie director. The history started from there.
When you think of people who shaped the World Wide Web, you probably picture founders and CEOs like Larry Page and Sergey Brin, Marc Andreesen, Tim Berners-Lee, Bill Gates, and Mark Zuckerberg. They’re undoubtedly the brightest people on earth.
Under these giants, legions of anonymous coders work at keyboards to create the systems and products we use. These computer workers are irreplaceable.
Let's get to know him better.
It's possible you've never heard of Jeff Dean. He's American. Dean created many behind-the-scenes Google products. Jeff, co-founder and head of Google's deep learning research engineering team, is a popular technology, innovation, and AI keynote speaker.
While earning an MS and Ph.D. in computer science at the University of Washington, he was a teaching assistant, instructor, and research assistant. Dean joined the Compaq Computer Corporation Western Research Laboratory research team after graduating.
Jeff co-created ProfileMe and the Continuous Profiling Infrastructure for Digital at Compaq. He co-designed and implemented Swift, one of the fastest Java implementations. He was a senior technical staff member at mySimon Inc., retrieving and caching electronic commerce content.
Dean, a top young computer scientist, joined Google in mid-1999. He was always trying to maximize a computer's potential as a child.
An expert
His high school program for processing massive epidemiological data was 26 times faster than professionals'. Epi Info, in 13 languages, is used by the CDC. He worked on compilers as a computer science Ph.D. These apps make source code computer-readable.
Dean never wanted to work on compilers forever. He left Academia for Google, which had less than 20 employees. Dean helped found Google News and AdSense, which transformed the internet economy. He then addressed Google's biggest issue, scaling.
Growing Google faced a huge computing challenge. They developed PageRank in the late 1990s to return the most relevant search results. Google's popularity slowed machine deployment.
Dean solved problems, his specialty. He and fellow great programmer Sanjay Ghemawat created the Google File System, which distributed large data over thousands of cheap machines.
These two also created MapReduce, which let programmers handle massive data quantities on parallel machines. They could also add calculations to the search algorithm. A 2004 research article explained MapReduce, which became an industry sensation.
Several revolutionary inventions
Dean's other initiatives were also game-changers. BigTable, a petabyte-capable distributed data storage system, was based on Google File. The first global database, Spanner, stores data on millions of servers in dozens of data centers worldwide.
It underpins Gmail and AdWords. Google Translate co-founder Jeff Dean is surprising. He contributes heavily to Google News. Dean is Senior Fellow of Google Research and Health and leads Google AI.
Recognitions
The National Academy of Engineering elected Dean in 2009. He received the 2009 Association for Computing Machinery fellowship and the 2016 American Academy of Arts and Science fellowship. He received the 2007 ACM-SIGOPS Mark Weiser Award and the 2012 ACM-Infosys Foundation Award. Lists could continue.
A sneaky question may arrive in your mind: How much does this big brain earn? Well, most believe he is one of the highest-paid employees at Google. According to a survey, he is paid $3 million a year.
He makes espresso and chats with a small group of Googlers most mornings. Dean steams milk, another grinds, and another brews espresso. They discuss families and technology while making coffee. He thinks this little collaboration and idea-sharing keeps Google going.
“Some of us have been working together for more than 15 years,” Dean said. “We estimate that we’ve collectively made more than 20,000 cappuccinos together.”
We all know great developers and software engineers. It may inspire many.

Will Lockett
3 years ago
The world will be changed by this molten salt battery.

Four times the energy density and a fraction of lithium-cost ion's
As the globe abandons fossil fuels, batteries become more important. EVs, solar, wind, tidal, wave, and even local energy grids will use them. We need a battery revolution since our present batteries are big, expensive, and detrimental to the environment. A recent publication describes a battery that solves these problems. But will it be enough?
Sodium-sulfur molten salt battery. It has existed for a long time and uses molten salt as an electrolyte (read more about molten salt batteries here). These batteries are cheaper, safer, and more environmentally friendly because they use less eco-damaging materials, are non-toxic, and are non-flammable.
Previous molten salt batteries used aluminium-sulphur chemistries, which had a low energy density and required high temperatures to keep the salt liquid. This one uses a revolutionary sodium-sulphur chemistry and a room-temperature-melting salt, making it more useful, affordable, and eco-friendly. To investigate this, researchers constructed a button-cell prototype and tested it.
First, the battery was 1,017 mAh/g. This battery is four times as energy dense as high-density lithium-ion batteries (250 mAh/g).
No one knows how much this battery would cost. A more expensive molten-salt battery costs $15 per kWh. Current lithium-ion batteries cost $132/kWh. If this new molten salt battery costs the same as present cells, it will be 90% cheaper.
This room-temperature molten salt battery could be utilized in an EV. Cold-weather heaters just need a modest backup battery.
The ultimate EV battery? If used in a Tesla Model S, you could install four times the capacity with no weight gain, offering a 1,620-mile range. This huge battery pack would cost less than Tesla's. This battery would nearly perfect EVs.
Or would it?
The battery's capacity declined by 50% after 1,000 charge cycles. This means that our hypothetical Model S would suffer this decline after 1.6 million miles, but for more cheap vehicles that use smaller packs, this would be too short. This test cell wasn't supposed to last long, so this is shocking. Future versions of this cell could be modified to live longer.
This affordable and eco-friendly cell is best employed as a grid-storage battery for renewable energy. Its safety and affordable price outweigh its short lifespan. Because this battery is made of easily accessible materials, it may be utilized to boost grid-storage capacity without causing supply chain concerns or EV battery prices to skyrocket.
Researchers are designing a bigger pouch cell (like those in phones and laptops) for this purpose. The battery revolution we need could be near. Let’s just hope it isn’t too late.

Shan Vernekar
3 years ago
How the Ethereum blockchain's transactions are carried out
Overview
Ethereum blockchain is a network of nodes that validate transactions. Any network node can be queried for blockchain data for free. To write data as a transition requires processing and writing to each network node's storage. Fee is paid in ether and is also called as gas.
We'll examine how user-initiated transactions flow across the network and into the blockchain.
Flow of transactions
A user wishes to move some ether from one external account to another. He utilizes a cryptocurrency wallet for this (like Metamask), which is a browser extension.
The user enters the desired transfer amount and the external account's address. He has the option to choose the transaction cost he is ready to pay.
Wallet makes use of this data, signs it with the user's private key, and writes it to an Ethereum node. Services such as Infura offer APIs that enable writing data to nodes. One of these services is used by Metamask. An example transaction is shown below. Notice the “to” address and value fields.
var rawTxn = {
nonce: web3.toHex(txnCount),
gasPrice: web3.toHex(100000000000),
gasLimit: web3.toHex(140000),
to: '0x633296baebc20f33ac2e1c1b105d7cd1f6a0718b',
value: web3.toHex(0),
data: '0xcc9ab24952616d6100000000000000000000000000000000000000000000000000000000'
};The transaction is written to the target Ethereum node's local TRANSACTION POOL. It informed surrounding nodes of the new transaction, and those nodes reciprocated. Eventually, this transaction is received by and written to each node's local TRANSACTION pool.
The miner who finds the following block first adds pending transactions (with a higher gas cost) from the nearby TRANSACTION POOL to the block.
The transactions written to the new block are verified by other network nodes.
A block is added to the main blockchain after there is consensus and it is determined to be genuine. The local blockchain is updated with the new node by additional nodes as well.
Block mining begins again next.
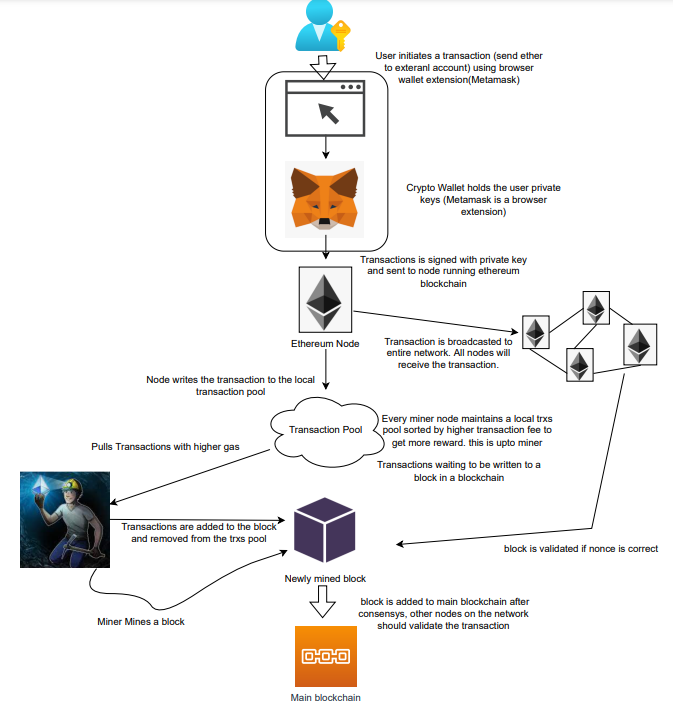
The image above shows how transactions go via the network and what's needed to submit them to the main block chain.
References
ethereum.org/transactions How Ethereum transactions function, their data structure, and how to send them via app. ethereum.org