


Apple WWDC 2022 Announcements
WWDC 2022 began early Tuesday morning. WWDC brought a ton of new features (which went for just shy of two hours).
With so many announcements, we thought we'd compile them. And now...
WWDC?
WWDC is Apple's developer conference. This includes iOS, macOS, watchOS, and iPadOS (all of its iPads). It's where Apple announces new features for developers to use. It's also where Apple previews new software.
Virtual WWDC runs June 6-10. You can rewatch the stream on Apple's website.
WWDC 2022 news:
Completely everything. Really. iOS 16 first.
iOS 16.
iOS 16 is a major iPhone update. iOS 16 adds the ability to customize the Lock Screen's color/theme. And widgets. It also organizes notifications and pairs Lock Screen with Focus themes. Edit or recall recently sent messages, recover recently deleted messages, and mark conversations as unread. Apple gives us yet another reason to stay in its walled garden with iMessage.
New iOS includes family sharing. Parents can set up a child's account with parental controls to restrict apps, movies, books, and music. iOS 16 lets large families and friend pods share iCloud photos. Up to six people can contribute photos to a separate iCloud library.
Live Text is getting creepier. Users can interact with text in any video frame. Touch and hold an image's subject to remove it from its background and place it in apps like messages. Dictation offers a new on-device voice-and-touch experience. Siri can run app shortcuts without setup in iOS 16. Apple also unveiled a new iOS 16 feature to help people break up with abusive partners who track their locations or read their messages. Safety Check.
Apple Pay Later allows iPhone users to buy products and pay for them later. iOS 16 pushes Mail. Users can schedule emails and cancel delivery before it reaches a recipient's inbox (be quick!). Mail now detects if you forgot an attachment, as Gmail has for years. iOS 16's Maps app gets "Multi-Stop Routing," .
Apple News also gets an iOS 16 update. Apple News adds My Sports. With iOS 16, the Apple Watch's Fitness app is also coming to iOS and the iPhone, using motion-sensing tech to track metrics and performance (as long as an athlete is wearing or carrying the device on their person).
iOS 16 includes accessibility updates like Door Detection.
watchOS9
Many of Apple's software updates are designed to take advantage of the larger screens in recent models, but they also improve health and fitness tracking.
The most obvious reason to upgrade watchOS every year is to get new watch faces from Apple. WatchOS 9 will add four new faces.
Runners' workout metrics improve.
Apple quickly realized that fitness tracking would be the Apple Watch's main feature, even though it's been the killer app for wearables since their debut. For watchOS 9, the Apple Watch will use its accelerometer and gyroscope to track a runner's form, stride length, and ground contact time. It also introduces the ability to specify heart rate zones, distance, and time intervals, with vibrating haptic feedback and voice alerts.
The Apple Watch's Fitness app is coming to iOS and the iPhone, using the smartphone's motion-sensing tech to track metrics and performance (as long as an athlete is wearing or carrying the device on their person).
We'll get sleep tracking, medication reminders, and drug interaction alerts. Your watch can create calendar events. A new Week view shows what meetings or responsibilities stand between you and the weekend.
iPadOS16
WWDC 2022 introduced iPad updates. iPadOS 16 is similar to iOS for the iPhone, but has features for larger screens and tablet accessories. The software update gives it many iPhone-like features.
iPadOS 16's Home app, like iOS 16, will have a new design language. iPad users who want to blame it on the rain finally have a Weather app. iPadOS 16 will have iCloud's Shared Photo Library, Live Text and Visual Look Up upgrades, and FaceTime Handoff, so you can switch between devices during a call.
Apple highlighted iPadOS 16's multitasking at WWDC 2022. iPad's Stage Manager sounds like a community theater app. It's a powerful multitasking tool for tablets and brings them closer to emulating laptops. Apple's iPadOS 16 supports multi-user collaboration. You can share content from Files, Keynote, Numbers, Pages, Notes, Reminders, Safari, and other third-party apps in Apple Messages.
M2-chip
WWDC 2022 revealed Apple's M2 chip. Apple has started the next generation of Apple Silicon for the Mac with M2. Apple says this device improves M1's performance.
M2's second-generation 5nm chip has 25% more transistors than M1's. 100GB/s memory bandwidth (50 per cent more than M1). M2 has 24GB of unified memory, up from 16GB but less than some ultraportable PCs' 32GB. The M2 chip has 10% better multi-core CPU performance than the M2, and it's nearly twice as fast as the latest 10-core PC laptop chip at the same power level (CPU performance is 18 per cent greater than M1).
New MacBooks
Apple introduced the M2-powered MacBook Air. Apple's entry-level laptop has a larger display, a new processor, new colors, and a notch.
M2 also powers the 13-inch MacBook Pro. The 13-inch MacBook Pro has 24GB of unified memory and 50% more memory bandwidth. New MacBook Pro batteries last 20 hours. As I type on the 2021 MacBook Pro, I can only imagine how much power the M2 will add.
macOS 13.0 (or, macOS Ventura)
macOS Ventura will take full advantage of M2 with new features like Stage Manager and Continuity Camera and Handoff for FaceTime. Safari, Mail, Messages, Spotlight, and more get updates in macOS Ventura.
Apple hasn't run out of California landmarks to name its OS after yet. macOS 13 will be called Ventura when it's released in a few months, but it's more than a name change and new wallpapers.
Stage Manager organizes windows
Stage Manager is a new macOS tool that organizes open windows and applications so they're still visible while focusing on a specific task. The main app sits in the middle of the desktop, while other apps and documents are organized and piled up to the side.
Improved Searching
Spotlight is one of macOS's least appreciated features, but with Ventura, it's becoming even more useful. Live Text lets you extract text from Spotlight results without leaving the window, including images from the photo library and the web.
Mail lets you schedule or unsend emails.
We've all sent an email we regret, whether it contained regrettable words or was sent at the wrong time. In macOS Ventura, Mail users can cancel or reschedule a message after sending it. Mail will now intelligently determine if a person was forgotten from a CC list or if a promised attachment wasn't included. Procrastinators can set a reminder to read a message later.
Safari adds tab sharing and password passkeys
Apple is updating Safari to make it more user-friendly... mostly. Users can share a group of tabs with friends or family, a useful feature when researching a topic with too many tabs. Passkeys will replace passwords in Safari's next version. Instead of entering random gibberish when creating a new account, macOS users can use TouchID to create an on-device passkey. Using an iPhone's camera and a QR system, Passkey syncs and works across all Apple devices and Windows computers.
Continuity adds Facetime device switching and iPhone webcam.
With macOS Ventura, iPhone users can transfer a FaceTime call from their phone to their desktop or laptop using Handoff, or vice versa if they started a call at their desk and need to continue it elsewhere. Apple finally admits its laptop and monitor webcams aren't the best. Continuity makes the iPhone a webcam. Apple demonstrated a feature where the wide-angle lens could provide a live stream of the desk below, while the standard zoom lens could focus on the speaker's face. New iPhone laptop mounts are coming.
System Preferences
System Preferences is Now System Settings and Looks Like iOS
Ventura's System Preferences has been renamed System Settings and is much more similar in appearance to iOS and iPadOS. As the iPhone and iPad are gateway devices into Apple's hardware ecosystem, new Mac users should find it easier to adjust.
This post is a summary. Read full article here
More on Technology

Gareth Willey
3 years ago
I've had these five apps on my phone for a long time.
TOP APPS
Who survives spring cleaning?

Relax. Notion is off-limits. This topic is popular.
(I wrote about it 2 years ago, before everyone else did.) So).
These apps are probably new to you. I hope you find a new phone app after reading this.
Outdooractive
ViewRanger is Google Maps for outdoor enthusiasts.
This app has been so important to me as a freedom-loving long-distance walker and hiker.
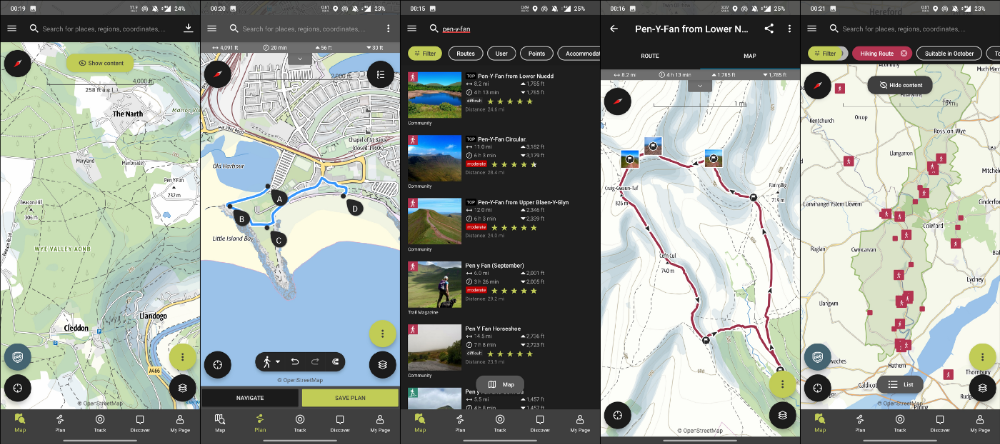
This app shows nearby trails and right-of-ways on top of an Open Street Map.
Helpful detail and data. Any route's distance,
You can download and follow tons of routes planned by app users.
This has helped me find new routes and places a fellow explorer has tried.
Free with non-intrusive ads. Years passed before I subscribed. Pro costs £2.23/month.

This app is for outdoor lovers.
Google Files
New phones come with bloatware. These rushed apps are frustrating.
We must replace these apps. 2017 was Google's year.
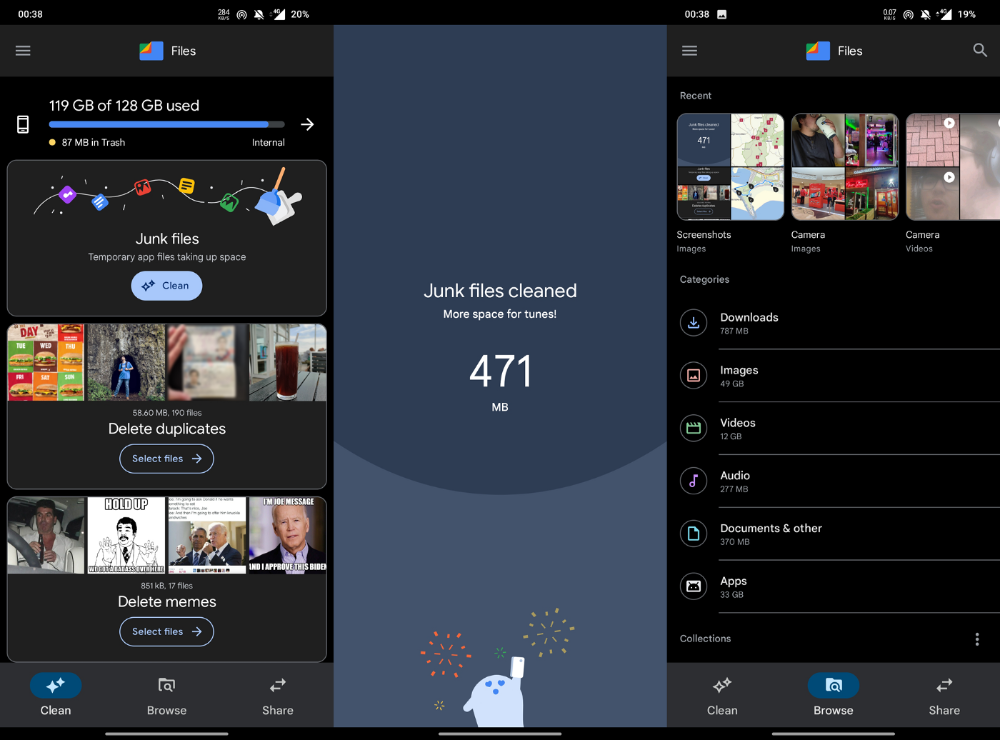
Files is a file manager. It's quick, innovative, and clean. They've given people what they want.
It's easy to organize files, clear space, and clear cache.
I recommend Gallery by Google as a gallery app alternative. It's quick and easy.
Trainline
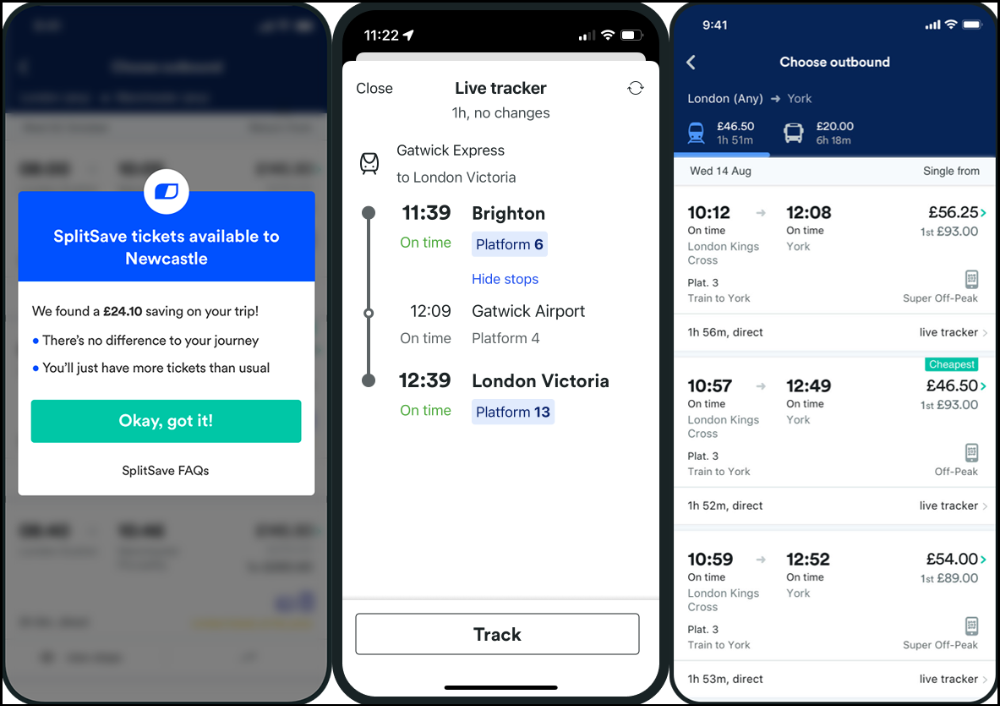
App for trains, buses, and coaches.
I've used this app for years. It did the basics well when I first used it.
Since then, it's improved. It's constantly adding features to make traveling easier and less stressful.
Split-ticketing helps me save hundreds a year on train fares. This app is only available in the UK and Europe.
This service doesn't link to a third-party site. Their app handles everything.
Not all train and coach companies use this app. All the big names are there, though.
Here's more on the app.
Battlefield: Mobile
Play Store has 478,000 games. Few can turn my phone into a console.
Call of Duty Mobile and Asphalt 8/9 are examples.
Asphalt's loot boxes and ads make it unplayable. Call of Duty opens with a few ads. Close them to play without hassle.
This game uses all your phone's features to provide a high-quality, seamless experience. If my internet connection is good, I never experience lag or glitches.
The gameplay is energizing and intense, just like on consoles. Sometimes I'm too involved. I've thrown my phone in anger. I'm totally absorbed.
Customizability is my favorite. Since phones have limited screen space, we should only have the buttons we need, placed conveniently.
Size, opacity, and position are modifiable. Adjust audio, graphics, and textures. It's customizable.
This game has been on my phone for three years. It began well and has gotten better. When I think the creators can't do more, they do.
If you play, read my tips for winning a Battle Royale.
Lightroom
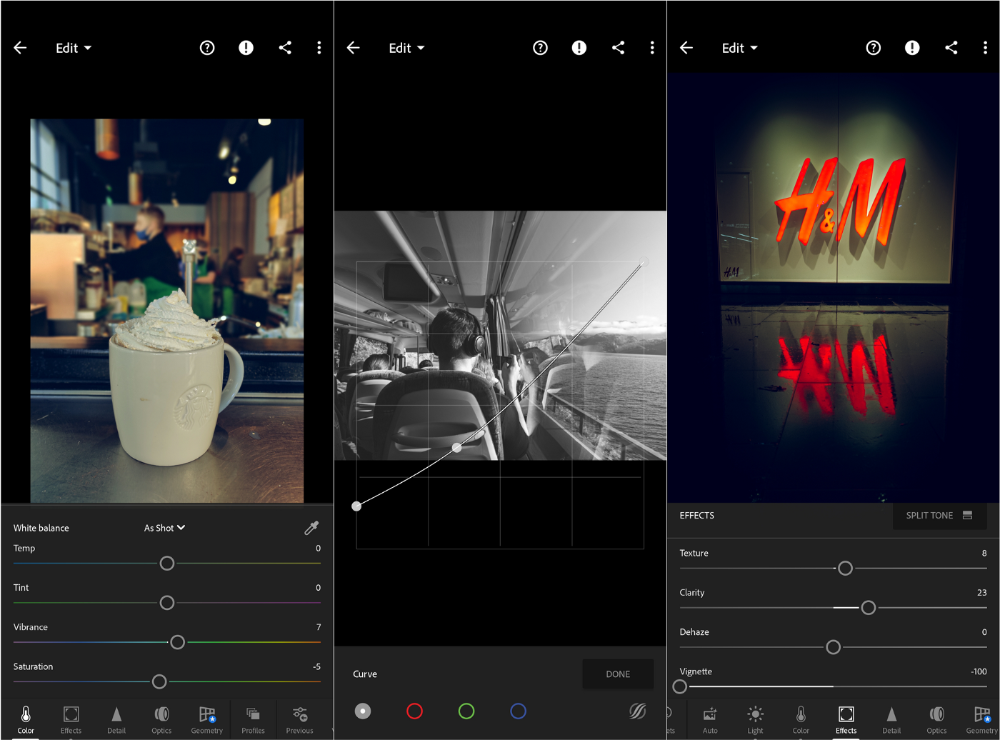
As a photographer, I believe your best camera is on you. The phone.
2017 was a big year for this app. I've tried many photo-editing apps since then. This always wins.
The app is dull. I've never seen better photo editing on a phone.
Adjusting settings and sliders doesn't damage or compress photos. It's detailed.
This is important for phone photos, which are lower quality than professional ones.
Some tools are behind a £4.49/month paywall. Adobe must charge a subscription fee instead of selling licenses. (I'm still bitter about Creative Cloud's price)
Snapseed is my pick. Lightroom is where I do basic editing before moving to Snapseed. Snapseed review:

These apps are great. They cover basic and complex editing needs while traveling.
Final Reflections
I hope you downloaded one of these. Share your favorite apps. These apps are scarce.

Tim Soulo
3 years ago
Here is why 90.63% of Pages Get No Traffic From Google.
The web adds millions or billions of pages per day.
How much Google traffic does this content get?
In 2017, we studied 2 million randomly-published pages to answer this question. Only 5.7% of them ranked in Google's top 10 search results within a year of being published.
94.3 percent of roughly two million pages got no Google traffic.
Two million pages is a small sample compared to the entire web. We did another study.
We analyzed over a billion pages to see how many get organic search traffic and why.
How many pages get search traffic?
90% of pages in our index get no Google traffic, and 5.2% get ten visits or less.
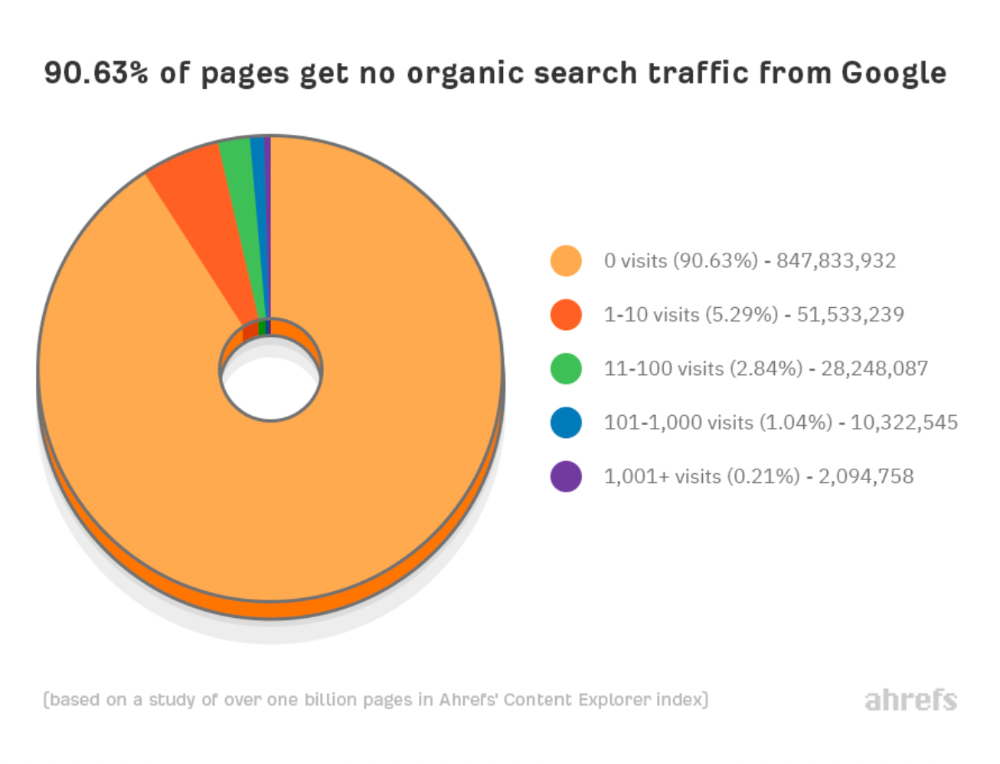
90% of google pages get no organic traffic
How can you join the minority that gets Google organic search traffic?
There are hundreds of SEO problems that can hurt your Google rankings. If we only consider common scenarios, there are only four.
Reason #1: No backlinks
I hate to repeat what most SEO articles say, but it's true:
Backlinks boost Google rankings.
Google's "top 3 ranking factors" include them.
Why don't we divide our studied pages by the number of referring domains?
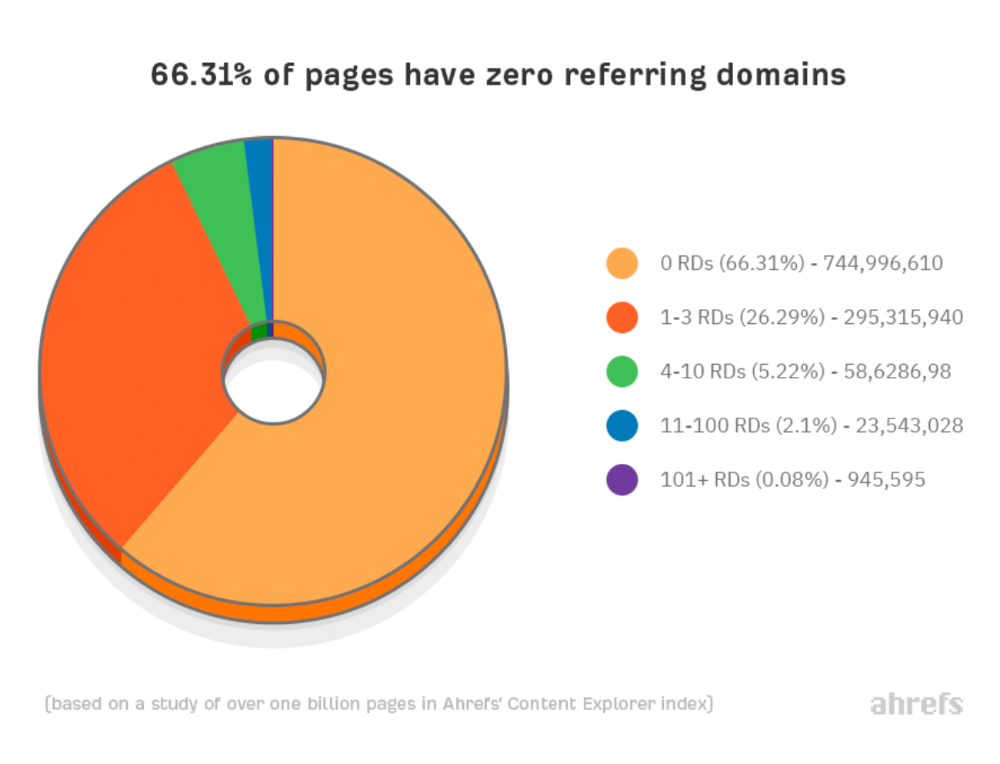
66.31 percent of pages have no backlinks, and 26.29 percent have three or fewer.
Did you notice the trend already?
Most pages lack search traffic and backlinks.
But are these the same pages?
Let's compare monthly organic search traffic to backlinks from unique websites (referring domains):
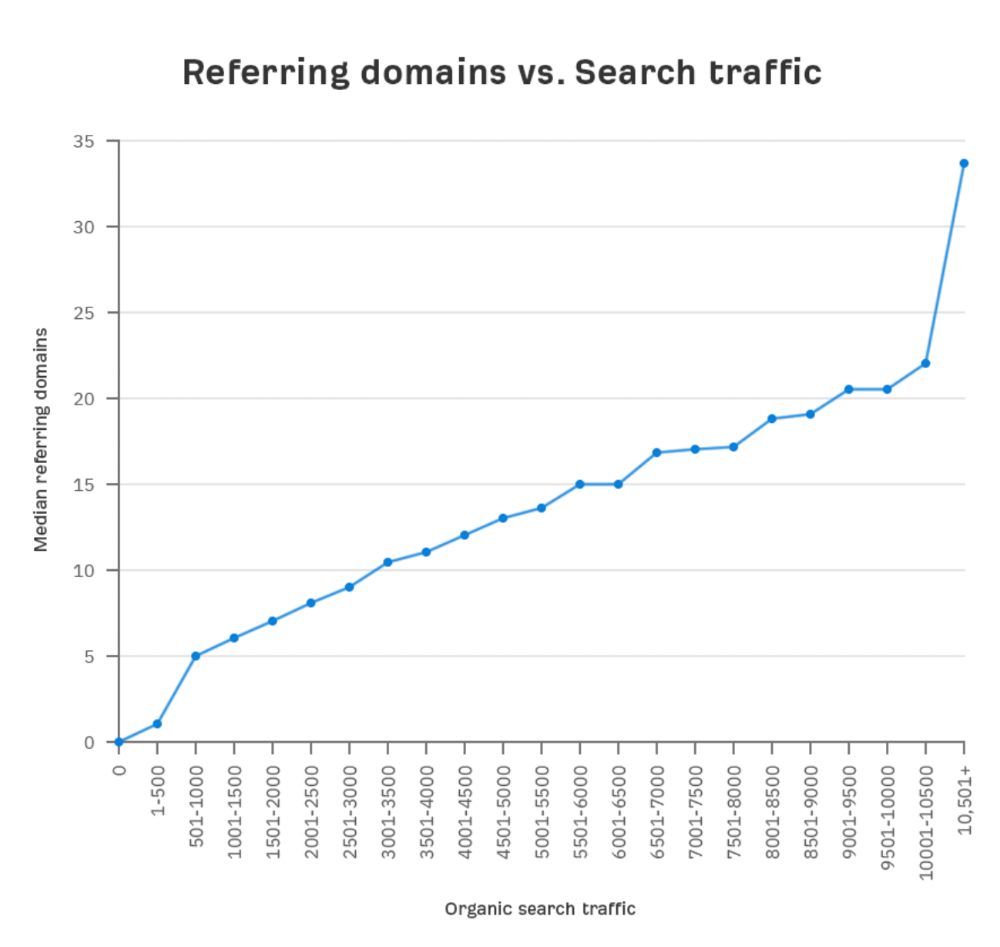
More backlinks equals more Google organic traffic.
Referring domains and keyword rankings are correlated.
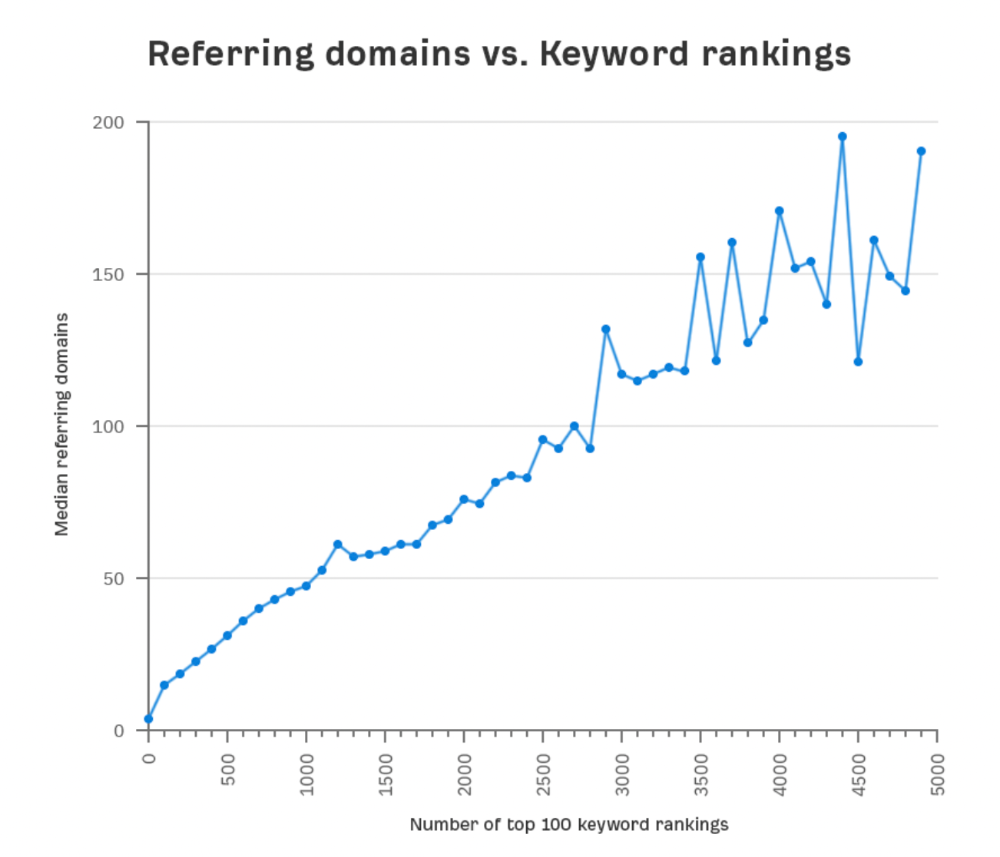
It's important to note that correlation does not imply causation, and none of these graphs prove backlinks boost Google rankings. Most SEO professionals agree that it's nearly impossible to rank on the first page without backlinks.
You'll need high-quality backlinks to rank in Google and get search traffic.
Is organic traffic possible without links?
Here are the numbers:
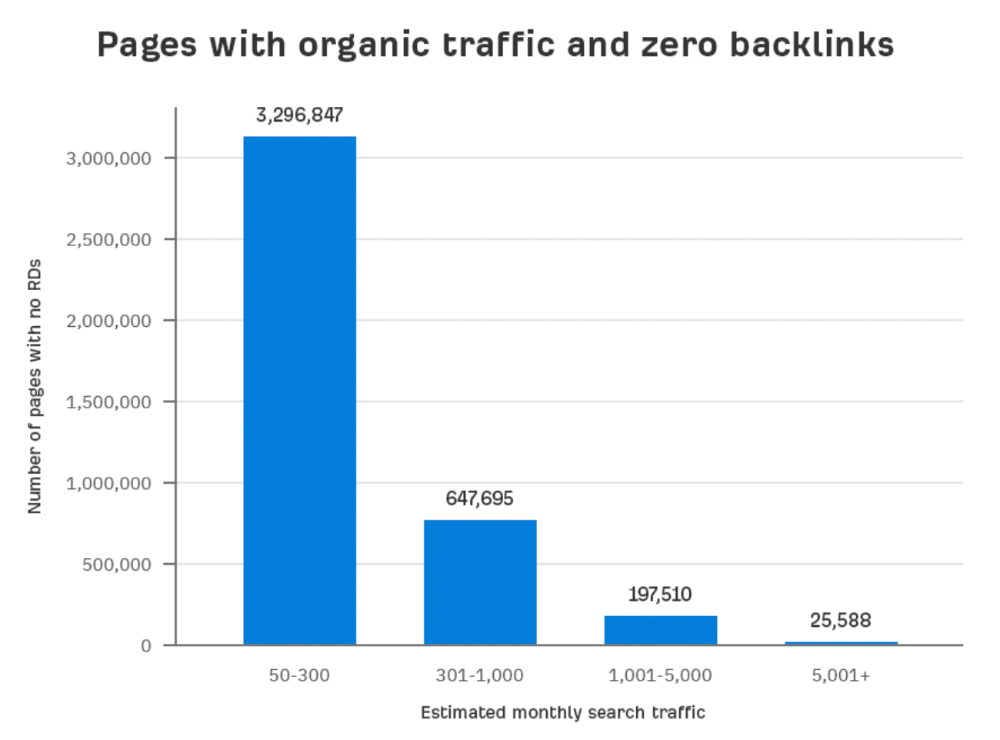
Four million pages get organic search traffic without backlinks. Only one in 20 pages without backlinks has traffic, which is 5% of our sample.
Most get 300 or fewer organic visits per month.
What happens if we exclude high-Domain-Rating pages?
The numbers worsen. Less than 4% of our sample (1.4 million pages) receive organic traffic. Only 320,000 get over 300 monthly organic visits, or 0.1% of our sample.
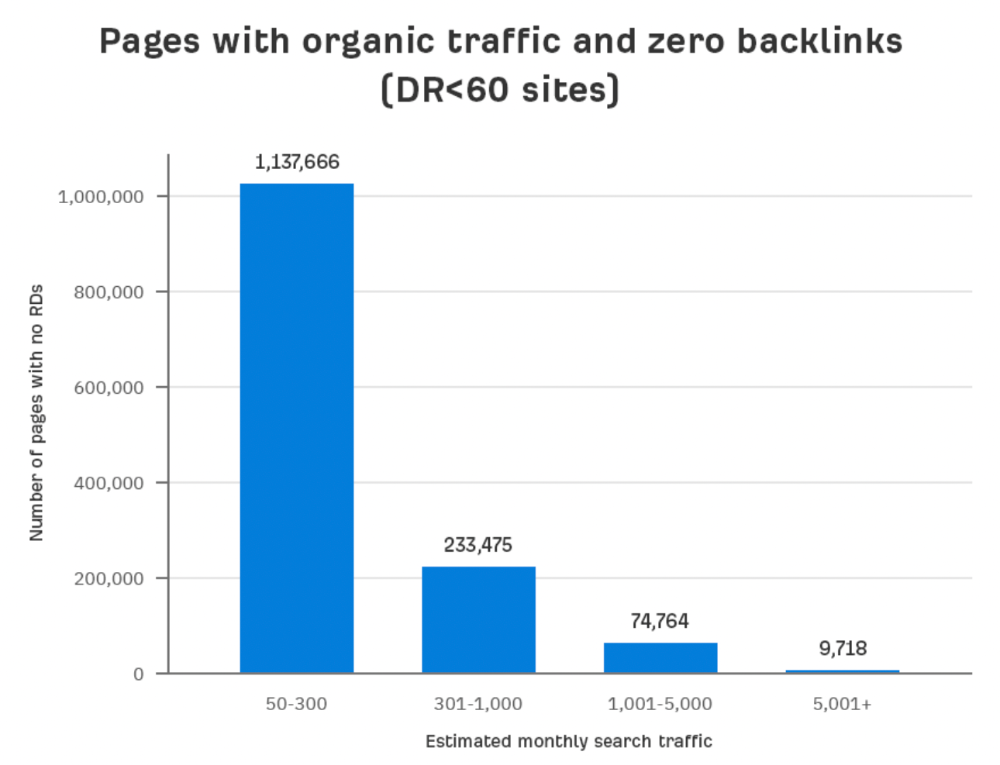
This suggests high-authority pages without backlinks are more likely to get organic traffic than low-authority pages.
Internal links likely pass PageRank to new pages.
Two other reasons:
Our crawler's blocked. Most shady SEOs block backlinks from us. This prevents competitors from seeing (and reporting) PBNs.
They choose low-competition subjects. Low-volume queries are less competitive, requiring fewer backlinks to rank.
If the idea of getting search traffic without building backlinks excites you, learn about Keyword Difficulty and how to find keywords/topics with decent traffic potential and low competition.
Reason #2: The page has no long-term traffic potential.
Some pages with many backlinks get no Google traffic.
Why? I filtered Content Explorer for pages with no organic search traffic and divided them into four buckets by linking domains.
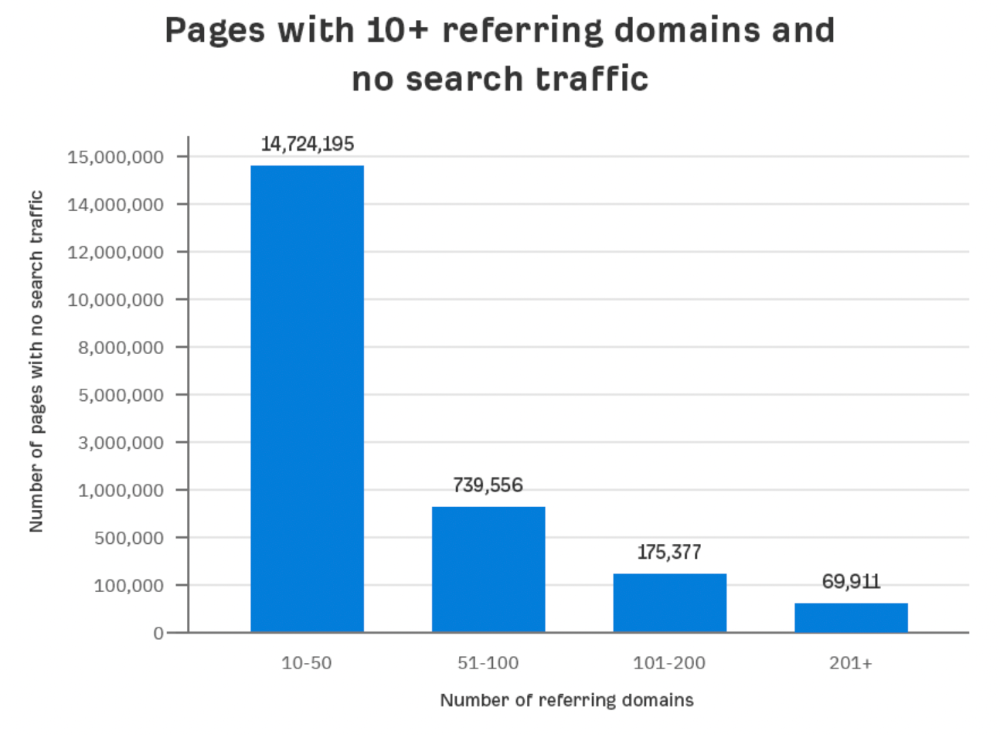
Almost 70k pages have backlinks from over 200 domains, but no search traffic.
By manually reviewing these (and other) pages, I noticed two general trends that explain why they get no traffic:
They overdid "shady link building" and got penalized by Google;
They're not targeting a Google-searched topic.
I won't elaborate on point one because I hope you don't engage in "shady link building"
#2 is self-explanatory:
If nobody searches for what you write, you won't get search traffic.
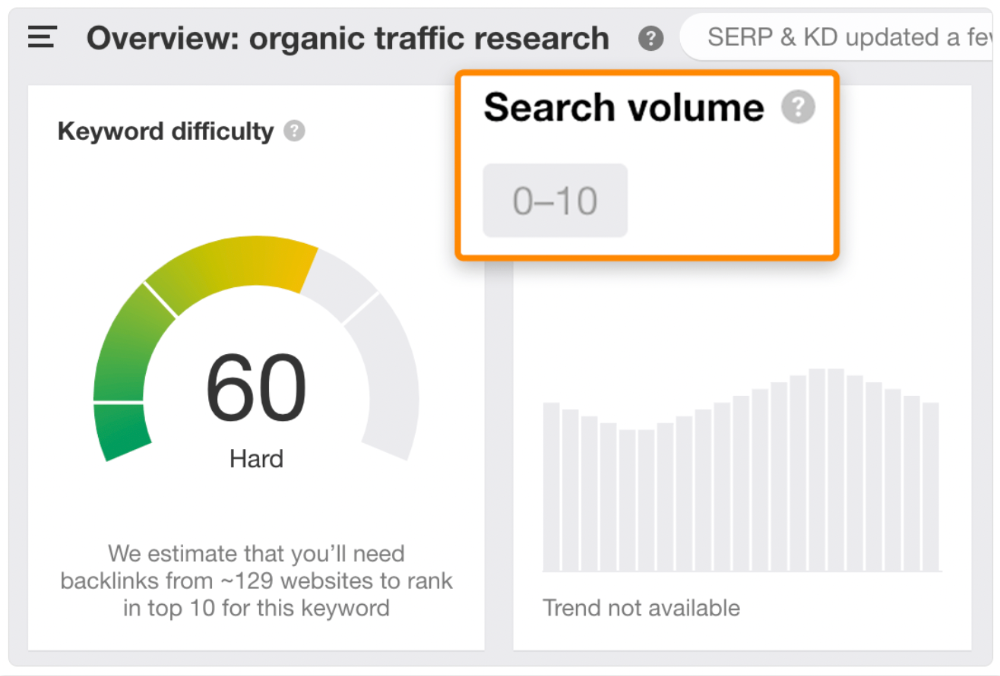
Consider one of our blog posts' metrics:

No organic traffic despite 337 backlinks from 132 sites.
The page is about "organic traffic research," which nobody searches for.
News articles often have this. They get many links from around the web but little Google traffic.
People can't search for things they don't know about, and most don't care about old events and don't search for them.
Note:
Some news articles rank in the "Top stories" block for relevant, high-volume search queries, generating short-term organic search traffic.
The Guardian's top "Donald Trump" story:
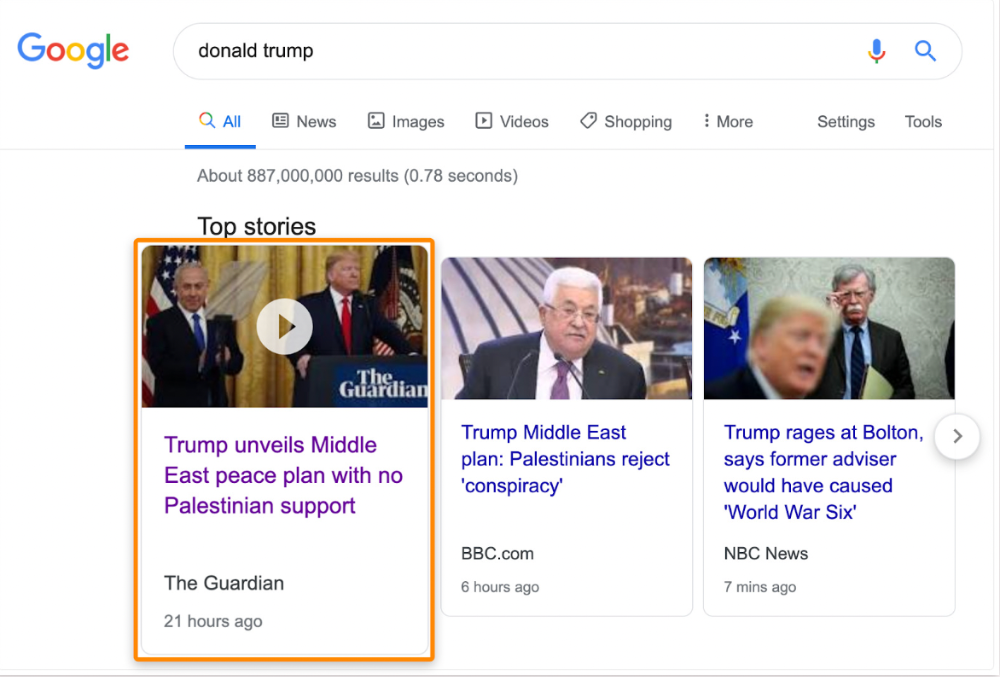
Ahrefs caught on quickly:
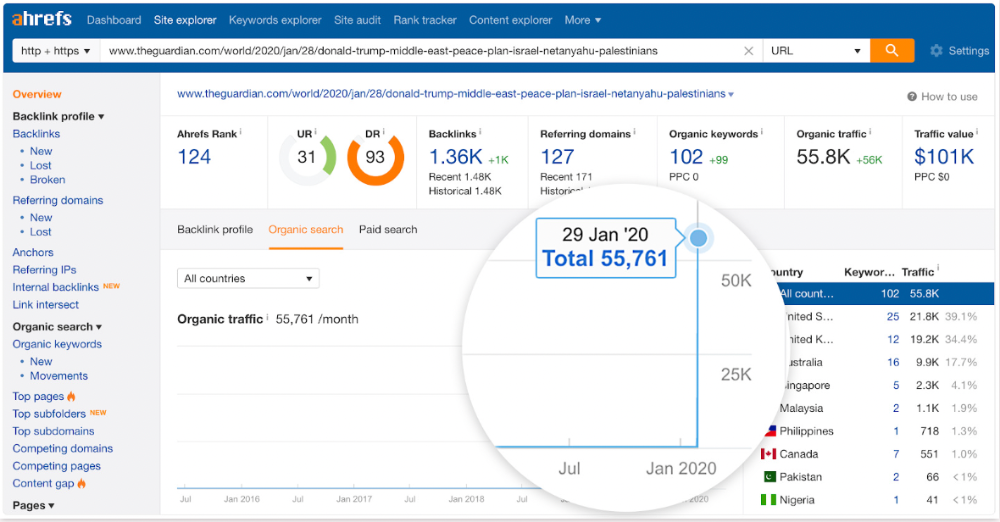
"Donald Trump" gets 5.6M monthly searches, so this page got a lot of "Top stories" traffic.
I bet traffic has dropped if you check now.
One of the quickest and most effective SEO wins is:
Find your website's pages with the most referring domains;
Do keyword research to re-optimize them for relevant topics with good search traffic potential.
Bryan Harris shared this "quick SEO win" during a course interview:
He suggested using Ahrefs' Site Explorer's "Best by links" report to find your site's most-linked pages and analyzing their search traffic. This finds pages with lots of links but little organic search traffic.
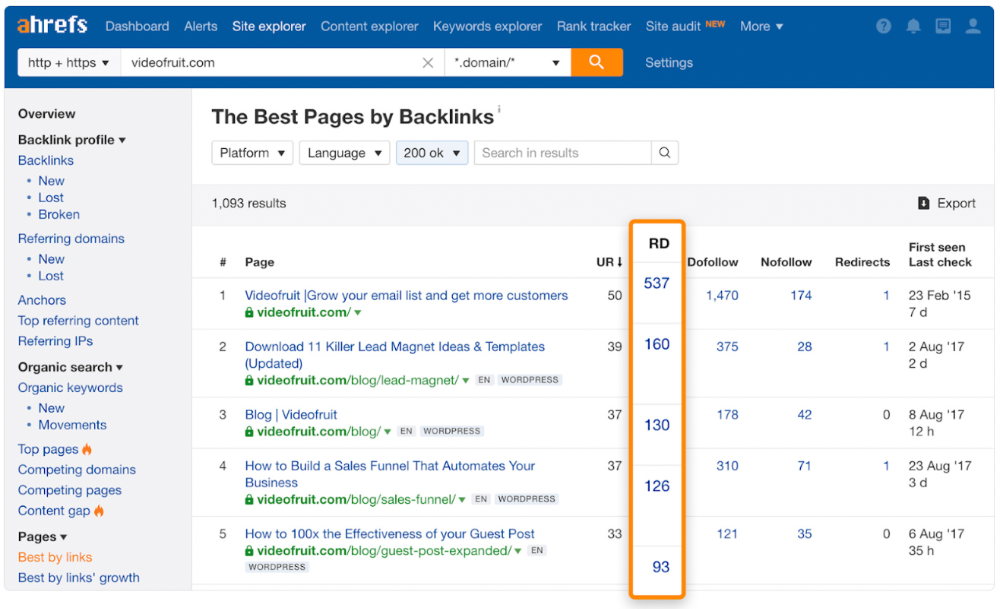
We see:
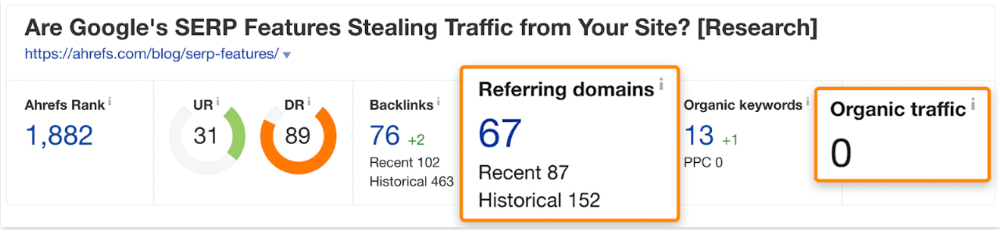
The guide has 67 backlinks but no organic traffic.
We could fix this by re-optimizing the page for "SERP"
A similar guide with 26 backlinks gets 3,400 monthly organic visits, so we should easily increase our traffic.
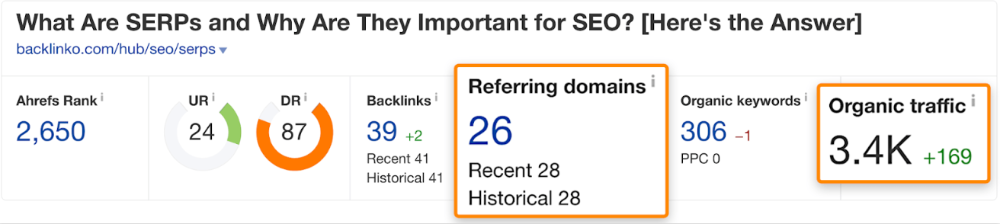
Don't do this with all low-traffic pages with backlinks. Choose your battles wisely; some pages shouldn't be ranked.
Reason #3: Search intent isn't met
Google returns the most relevant search results.
That's why blog posts with recommendations rank highest for "best yoga mat."
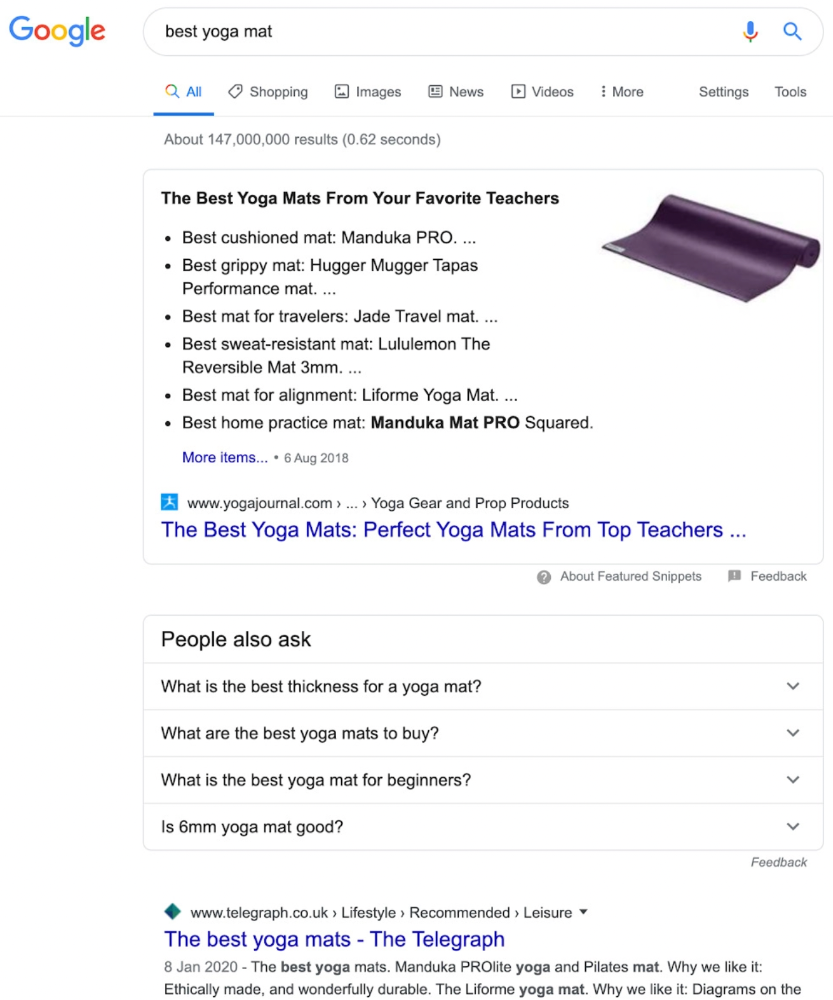
Google knows that most searchers aren't buying.
It's also why this yoga mats page doesn't rank, despite having seven times more backlinks than the top 10 pages:
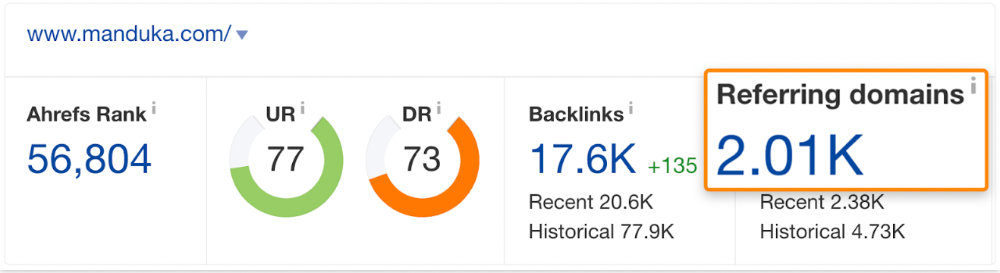
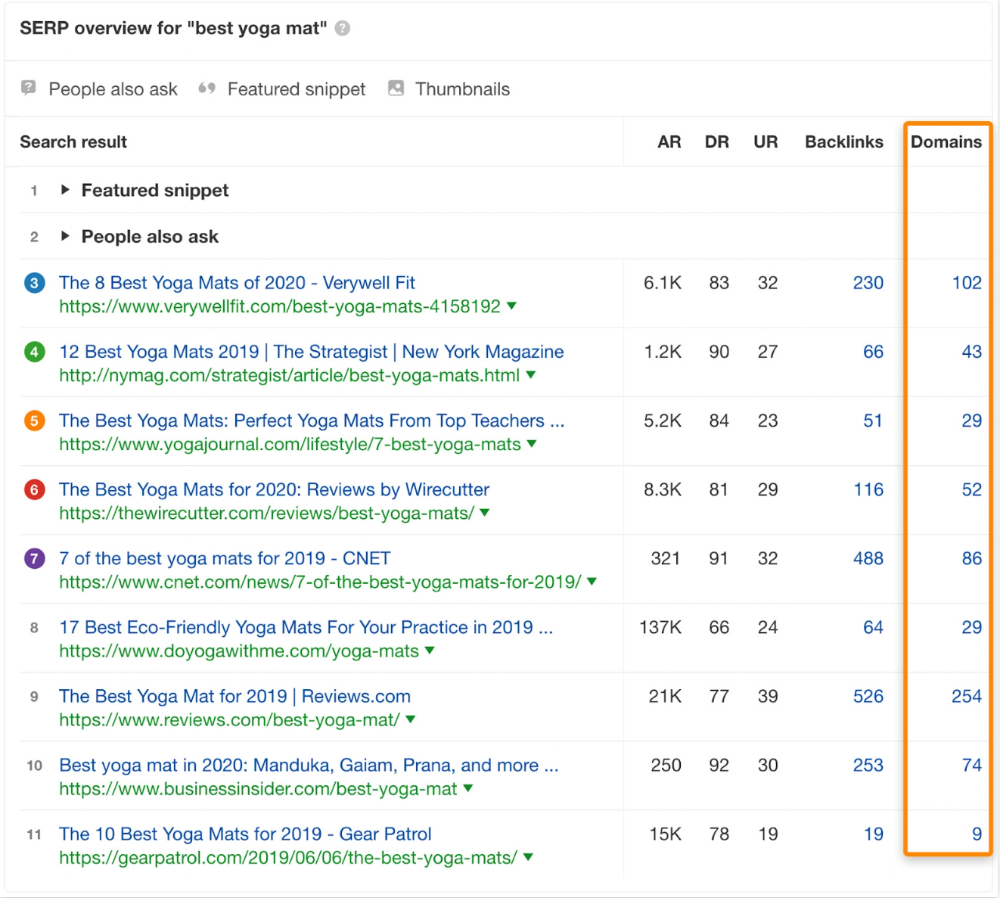
The page ranks for thousands of other keywords and gets tens of thousands of monthly organic visits. Not being the "best yoga mat" isn't a big deal.
If you have pages with lots of backlinks but no organic traffic, re-optimizing them for search intent can be a quick SEO win.
It was originally a boring landing page describing our product's benefits and offering a 7-day trial.
We realized the problem after analyzing search intent.
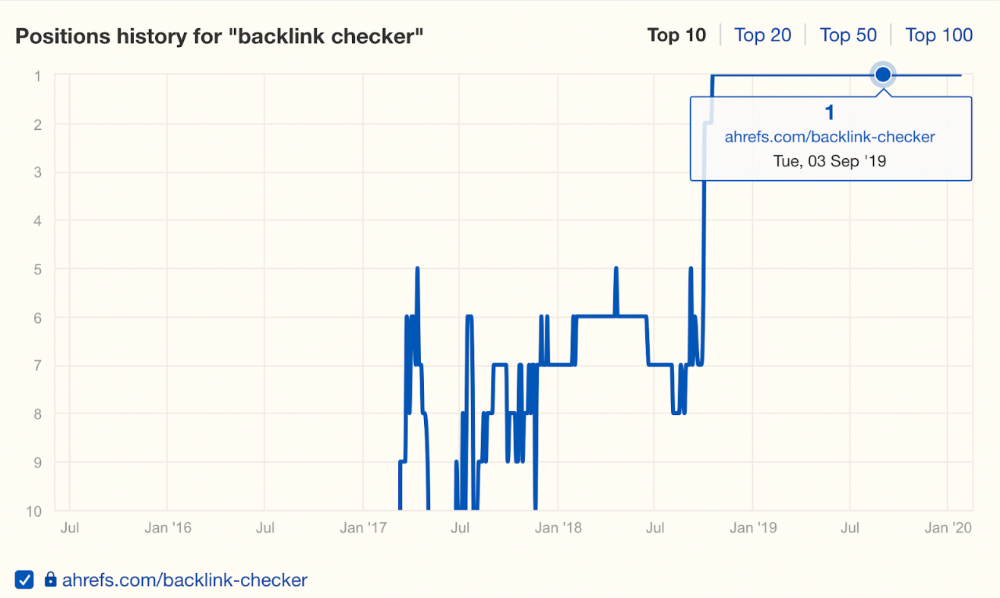
People wanted a free tool, not a landing page.
In September 2018, we published a free tool at the same URL. Organic traffic and rankings skyrocketed.
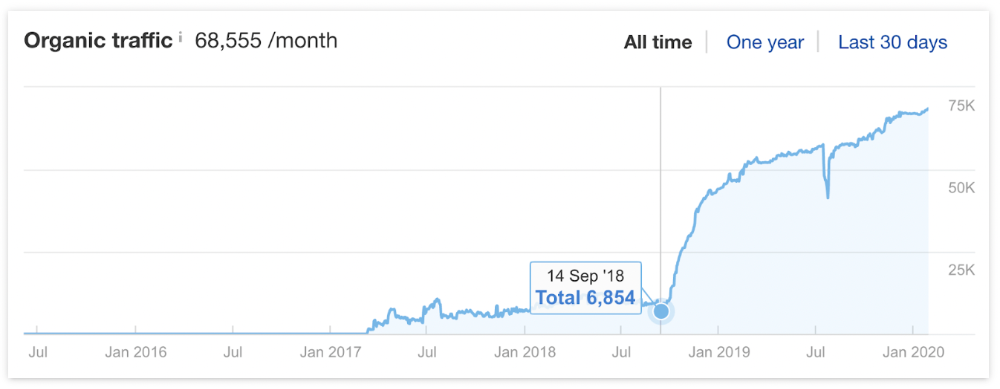
Reason #4: Unindexed page
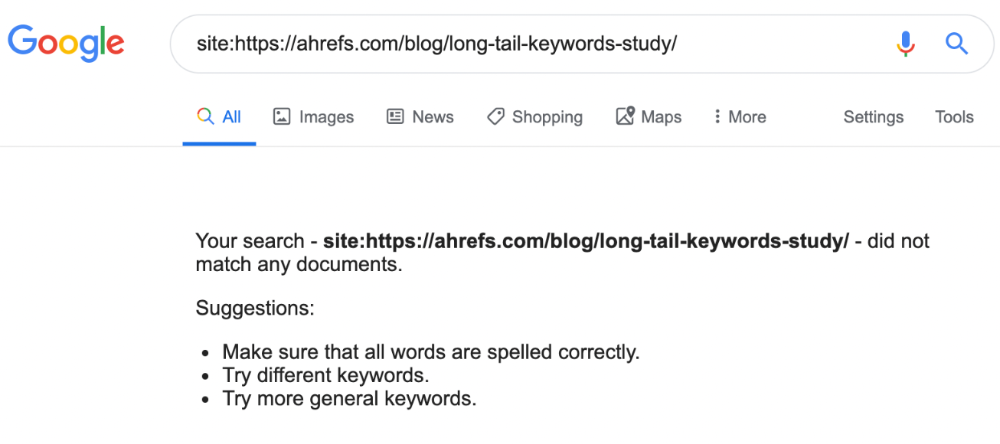
Google can’t rank pages that aren’t indexed.
If you think this is the case, search Google for site:[url]. You should see at least one result; otherwise, it’s not indexed.
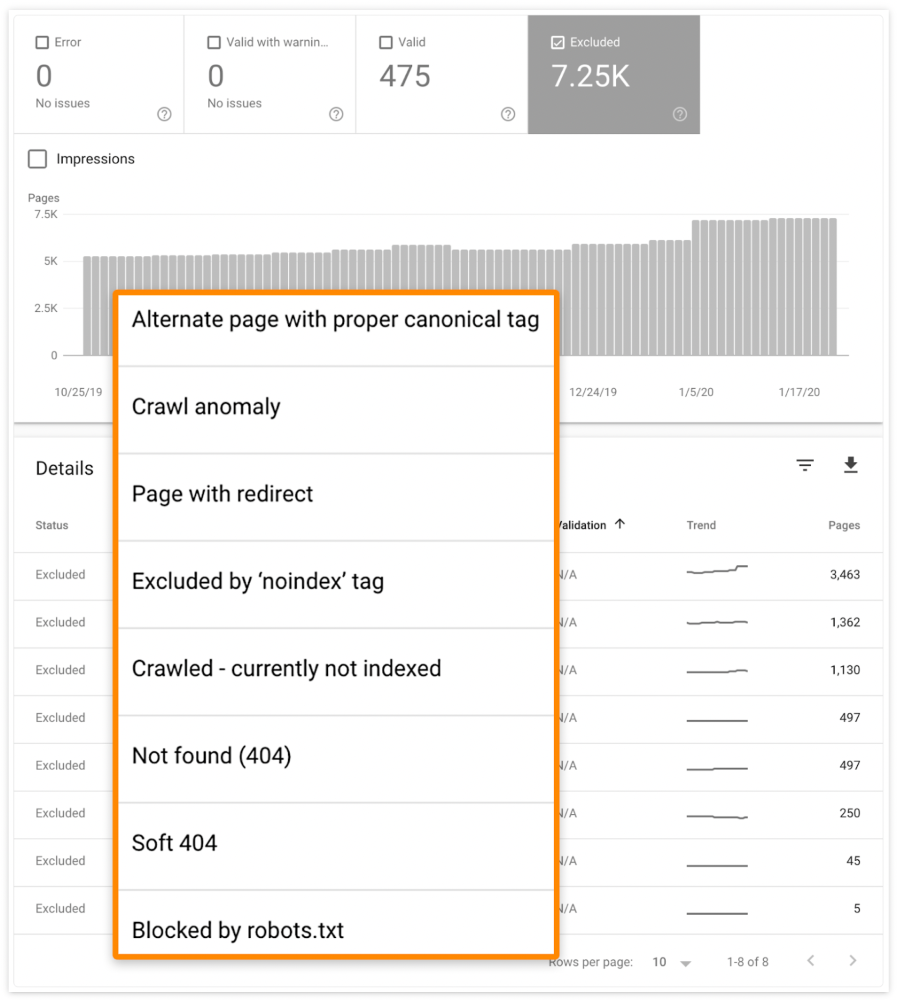
A rogue noindex meta tag is usually to blame. This tells search engines not to index a URL.
Rogue canonicals, redirects, and robots.txt blocks prevent indexing.
Check the "Excluded" tab in Google Search Console's "Coverage" report to see excluded pages.
Google doesn't index broken pages, even with backlinks.
Surprisingly common.
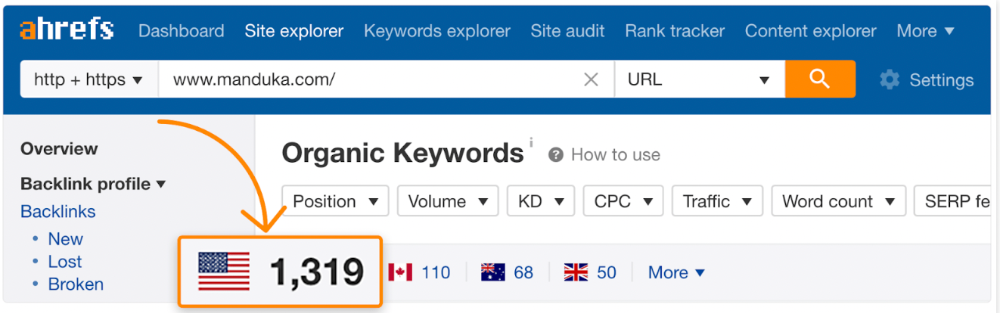
In Ahrefs' Site Explorer, the Best by Links report for a popular content marketing blog shows many broken pages.
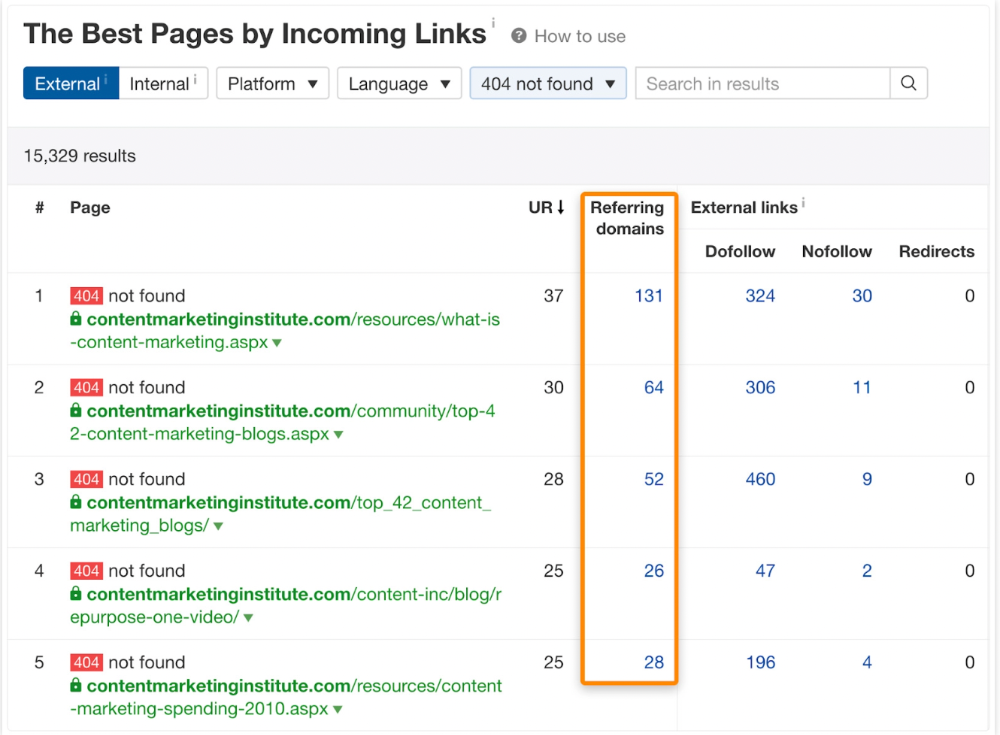
One dead page has 131 backlinks:
According to the URL, the page defined content marketing. —a keyword with a monthly search volume of 5,900 in the US.
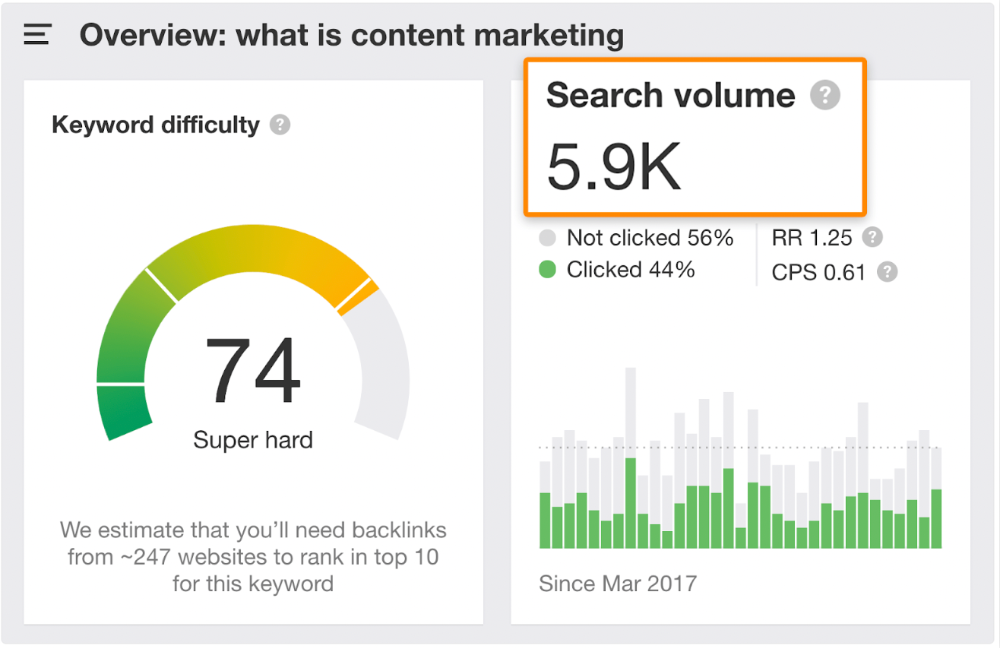
Luckily, another page ranks for this keyword. Not a huge loss.
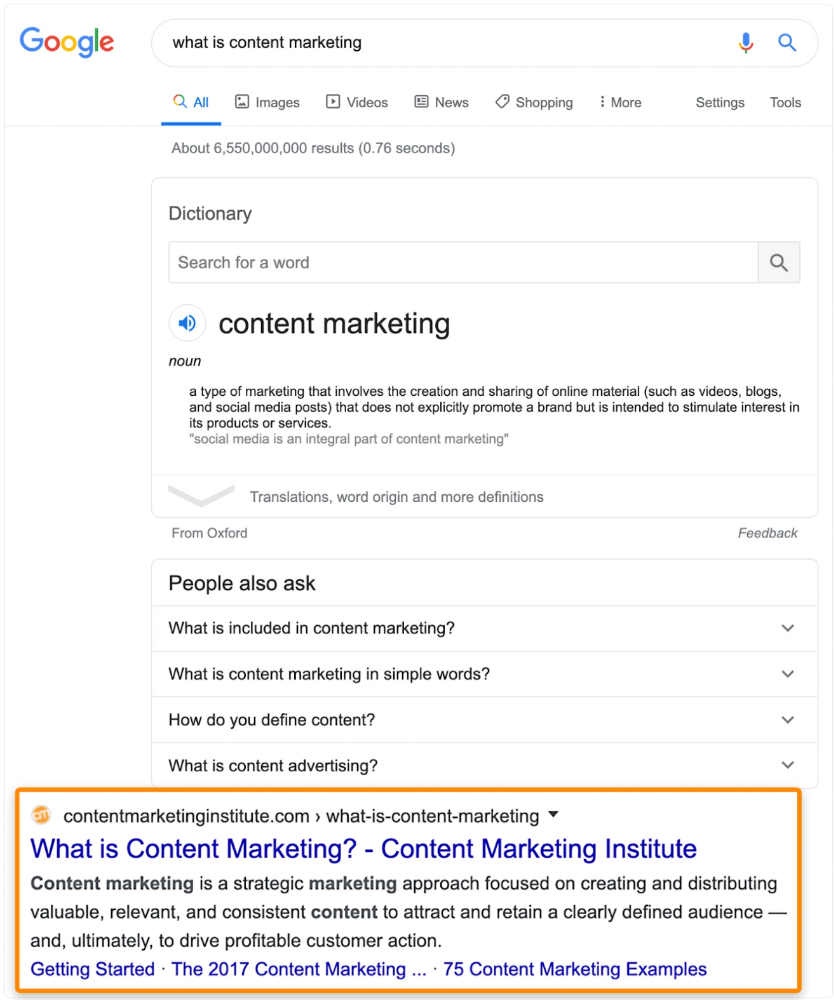
At least redirect the dead page's backlinks to a working page on the same topic. This may increase long-tail keyword traffic.
This post is a summary. See the original post here

Duane Michael
3 years ago
Don't Fall Behind: 7 Subjects You Must Understand to Keep Up with Technology
As technology develops, you should stay up to date

You don't want to fall behind, do you? This post covers 7 tech-related things you should know.
You'll learn how to operate your computer (and other electronic devices) like an expert and how to leverage the Internet and social media to create your brand and business. Read on to stay relevant in today's tech-driven environment.
You must learn how to code.
Future-language is coding. It's how we and computers talk. Learn coding to keep ahead.
Try Codecademy or Code School. There are also numerous free courses like Coursera or Udacity, but they take a long time and aren't necessarily self-paced, so it can be challenging to find the time.
Artificial intelligence (AI) will transform all jobs.
Our skillsets must adapt with technology. AI is a must-know topic. AI will revolutionize every employment due to advances in machine learning.
Here are seven AI subjects you must know.
What is artificial intelligence?
How does artificial intelligence work?
What are some examples of AI applications?
How can I use artificial intelligence in my day-to-day life?
What jobs have a high chance of being replaced by artificial intelligence and how can I prepare for this?
Can machines replace humans? What would happen if they did?
How can we manage the social impact of artificial intelligence and automation on human society and individual people?
Blockchain Is Changing the Future
Few of us know how Bitcoin and blockchain technology function or what impact they will have on our lives. Blockchain offers safe, transparent, tamper-proof transactions.
It may alter everything from business to voting. Seven must-know blockchain topics:
Describe blockchain.
How does the blockchain function?
What advantages does blockchain offer?
What possible uses for blockchain are there?
What are the dangers of blockchain technology?
What are my options for using blockchain technology?
What does blockchain technology's future hold?
Cryptocurrencies are here to stay
Cryptocurrencies employ cryptography to safeguard transactions and manage unit creation. Decentralized cryptocurrencies aren't controlled by governments or financial institutions.

Bitcoin, the first cryptocurrency, was launched in 2009. Cryptocurrencies can be bought and sold on decentralized exchanges.
Bitcoin is here to stay.
Bitcoin isn't a fad, despite what some say. Since 2009, Bitcoin's popularity has grown. Bitcoin is worth learning about now. Since 2009, Bitcoin has developed steadily.
With other cryptocurrencies emerging, many people are wondering if Bitcoin still has a bright future. Curiosity is natural. Millions of individuals hope their Bitcoin investments will pay off since they're popular now.
Thankfully, they will. Bitcoin is still running strong a decade after its birth. Here's why.
The Internet of Things (IoT) is no longer just a trendy term.
IoT consists of internet-connected physical items. These items can share data. IoT is young but developing fast.
20 billion IoT-connected devices are expected by 2023. So much data! All IT teams must keep up with quickly expanding technologies. Four must-know IoT topics:
Recognize the fundamentals: Priorities first! Before diving into more technical lingo, you should have a fundamental understanding of what an IoT system is. Before exploring how something works, it's crucial to understand what you're working with.
Recognize Security: Security does not stand still, even as technology advances at a dizzying pace. As IT professionals, it is our duty to be aware of the ways in which our systems are susceptible to intrusion and to ensure that the necessary precautions are taken to protect them.
Be able to discuss cloud computing: The cloud has seen various modifications over the past several years once again. The use of cloud computing is also continually changing. Knowing what kind of cloud computing your firm or clients utilize will enable you to make the appropriate recommendations.
Bring Your Own Device (BYOD)/Mobile Device Management (MDM) is a topic worth discussing (MDM). The ability of BYOD and MDM rules to lower expenses while boosting productivity among employees who use these services responsibly is a major factor in their continued growth in popularity.
IoT Security is key
As more gadgets connect, they must be secure. IoT security includes securing devices and encrypting data. Seven IoT security must-knows:
fundamental security ideas
Authorization and identification
Cryptography
electronic certificates
electronic signatures
Private key encryption
Public key encryption
Final Thoughts
With so much going on in the globe, it can be hard to stay up with technology. We've produced a list of seven tech must-knows.
You might also like
JEFF JOHN ROBERTS
3 years ago
What just happened in cryptocurrency? A plain-English Q&A about Binance's FTX takedown.

Crypto people have witnessed things. They've seen big hacks, mind-boggling swindles, and amazing successes. They've never seen a day like Tuesday, when the world's largest crypto exchange murdered its closest competition.
Here's a primer on Binance and FTX's lunacy and why it matters if you're new to crypto.
What happened?
CZ, a shrewd Chinese-Canadian billionaire, runs Binance. FTX, a newcomer, has challenged Binance in recent years. SBF (Sam Bankman-Fried)—a young American with wild hair—founded FTX (initials are a thing in crypto).
Last weekend, CZ complained about SBF's lobbying and then exploited Binance's market power to attack his competition.
How did CZ do that?
CZ invested in SBF's new cryptocurrency exchange when they were friends. CZ sold his investment in FTX for FTT when he no longer wanted it. FTX clients utilize those tokens to get trade discounts, although they are less liquid than Bitcoin.
SBF made a mistake by providing CZ just too many FTT tokens, giving him control over FTX. It's like Pepsi handing Coca-Cola a lot of stock it could sell at any time. CZ got upset with SBF and flooded the market with FTT tokens.
SBF owns a trading fund with many FTT tokens, therefore this was catastrophic. SBF sought to defend FTT's worth by selling other assets to buy up the FTT tokens flooding the market, but it didn't succeed, and as FTT's value plummeted, his liabilities exceeded his assets. By Tuesday, his companies were insolvent, so he sold them to his competition.
Crazy. How could CZ do that?
CZ likely did this to crush a rising competition. It was also personal. In recent months, regulators have been tough toward the crypto business, and Binance and FTX have been trying to stay on their good side. CZ believed SBF was poisoning U.S. authorities by saying CZ was linked to China, so CZ took retribution.
“We supported previously, but we won't pretend to make love after divorce. We're neutral. But we won't assist people that push against other industry players behind their backs," CZ stated in a tragic tweet on Sunday. He crushed his rival's company two days later.
So does Binance now own FTX?
No. Not yet. CZ has only stated that Binance signed a "letter of intent" to acquire FTX. CZ and SBF say Binance will protect FTX consumers' funds.
Who’s to blame?
You could blame CZ for using his control over FTX to destroy it. SBF is also being criticized for not disclosing the full overlap between FTX and his trading company, which controlled plenty of FTT. If he had been upfront, someone might have warned FTX about this vulnerability earlier, preventing this mess.
Others have alleged that SBF utilized customer monies to patch flaws in his enterprises' balance accounts. That happened to multiple crypto startups that collapsed this spring, which is unfortunate. These are allegations, not proof.
Why does this matter? Isn't this common in crypto?
Crypto is notorious for shady executives and pranks. FTX is the second-largest crypto business, and SBF was largely considered as the industry's golden boy who would help it get on authorities' good side. Thus far.
Does this affect cryptocurrency prices?
Short-term, it's bad. Prices fell on suspicions that FTX was in peril, then rallied when Binance rescued it, only to fall again later on Tuesday.
These occurrences have hurt FTT and SBF's Solana token. It appears like a huge token selloff is affecting the rest of the market. Bitcoin fell 10% and Ethereum 15%, which is bad but not catastrophic for the two largest coins by market cap.

Edward Williams
3 years ago
I currently manage 4 profitable online companies. I find all the generic advice and garbage courses very frustrating. The only advice you need is this.

This is for young entrepreneurs, especially in tech.
People give useless success advice on TikTok and Reddit. Early risers, bookworms, etc. Entrepreneurship courses. Work hard and hustle.
False. These aren't successful traits.
I mean, organization is good. As someone who founded several businesses and now works at a VC firm, I find these tips to be clichés.
Based on founding four successful businesses and working with other successful firms, here's my best actionable advice:
1. Choose a sector or a niche and become an expert in it.
This is more generic than my next tip, but it's a must-do that's often overlooked. Become an expert in the industry or niche you want to enter. Discover everything.
Buy (future) competitors' products. Understand consumers' pain points. Market-test. Target keyword combos. Learn technical details.
The most successful businesses I've worked with were all formed by 9-5 employees. They knew the industry's pain points. They started a business targeting these pain points.
2. Choose a niche or industry crossroads to target.
How do you choose an industry or niche? What if your industry is too competitive?
List your skills and hobbies. Randomness is fine. Find an intersection between two interests or skills.
Say you build websites well. You like cars.
Web design is a *very* competitive industry. Cars and web design?
Instead of web design, target car dealers and mechanics. Build a few fake demo auto mechanic websites, then cold call shops with poor websites. Verticalize.
I've noticed a pattern:
Person works in a particular industry for a corporation.
Person gains expertise in the relevant industry.
Person quits their job and launches a small business to address a problem that their former employer was unwilling to address.
I originally posted this on Reddit and it seemed to have taken off so I decided to share it with you all.
Focus on the product. When someone buys from you, you convince them the product's value exceeds the price. It's not fair and favors the buyer.
Creating a superior product or service will win. Narrowing this helps you outcompete others.
You may be their only (lucky) option.

Laura Sanders
3 years ago
Xenobots, tiny living machines, can duplicate themselves.
Strange and complex behavior of frog cell blobs
A xenobot “parent,” shaped like a hungry Pac-Man (shown in red false color), created an “offspring” xenobot (green sphere) by gathering loose frog cells in its opening.
Tiny “living machines” made of frog cells can make copies of themselves. This newly discovered renewal mechanism may help create self-renewing biological machines.
According to Kirstin Petersen, an electrical and computer engineer at Cornell University who studies groups of robots, “this is an extremely exciting breakthrough.” She says self-replicating robots are a big step toward human-free systems.
Researchers described the behavior of xenobots earlier this year (SN: 3/31/21). Small clumps of skin stem cells from frog embryos knitted themselves into small spheres and started moving. Cilia, or cellular extensions, powered the xenobots around their lab dishes.
The findings are published in the Proceedings of the National Academy of Sciences on Dec. 7. The xenobots can gather loose frog cells into spheres, which then form xenobots.
The researchers call this type of movement-induced reproduction kinematic self-replication. The study's coauthor, Douglas Blackiston of Tufts University in Medford, Massachusetts, and Harvard University, says this is typical. For example, sexual reproduction requires parental sperm and egg cells. Sometimes cells split or budded off from a parent.
“This is unique,” Blackiston says. These xenobots “find loose parts in the environment and cobble them together.” This second generation of xenobots can move like their parents, Blackiston says.
The researchers discovered that spheroid xenobots could only produce one more generation before dying out. The original xenobots' shape was predicted by an artificial intelligence program, allowing for four generations of replication.
A C shape, like an openmouthed Pac-Man, was predicted to be a more efficient progenitor. When improved xenobots were let loose in a dish, they began scooping up loose cells into their gaping “mouths,” forming more sphere-shaped bots (see image below). As many as 50 cells clumped together in the opening of a parent to form a mobile offspring. A xenobot is made up of 4,000–6,000 frog cells.
Petersen likes the Xenobots' small size. “The fact that they were able to do this at such a small scale just makes it even better,” she says. Miniature xenobots could sculpt tissues for implantation or deliver therapeutics inside the body.
Beyond the xenobots' potential jobs, the research advances an important science, says study coauthor and Tufts developmental biologist Michael Levin. The science of anticipating and controlling the outcomes of complex systems, he says.
“No one could have predicted this,” Levin says. “They regularly surprise us.” Researchers can use xenobots to test the unexpected. “This is about advancing the science of being less surprised,” Levin says.