























More on Technology

Gareth Willey
3 years ago
I've had these five apps on my phone for a long time.
TOP APPS
Who survives spring cleaning?

Relax. Notion is off-limits. This topic is popular.
(I wrote about it 2 years ago, before everyone else did.) So).
These apps are probably new to you. I hope you find a new phone app after reading this.
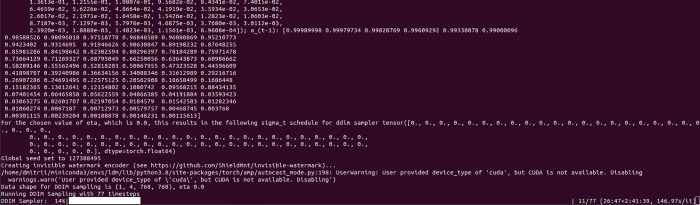
Outdooractive
ViewRanger is Google Maps for outdoor enthusiasts.
This app has been so important to me as a freedom-loving long-distance walker and hiker.
This app shows nearby trails and right-of-ways on top of an Open Street Map.
Helpful detail and data. Any route's distance,
You can download and follow tons of routes planned by app users.
This has helped me find new routes and places a fellow explorer has tried.
Free with non-intrusive ads. Years passed before I subscribed. Pro costs £2.23/month.

This app is for outdoor lovers.
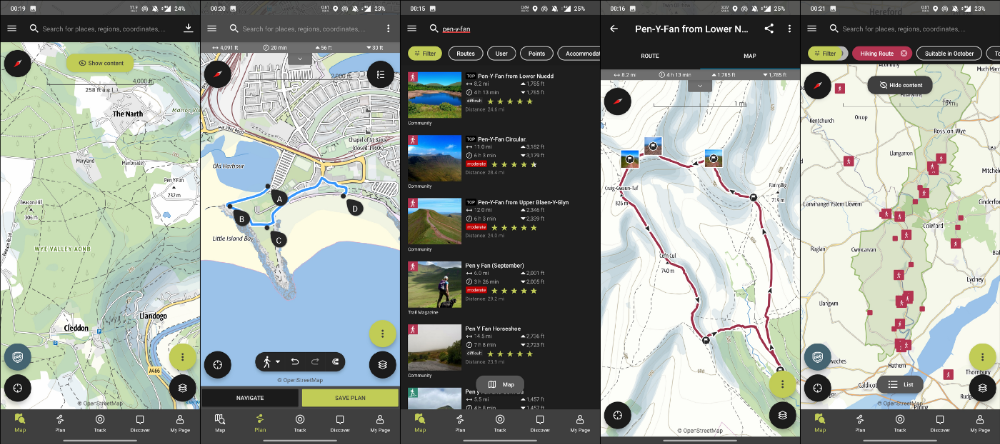
Google Files
New phones come with bloatware. These rushed apps are frustrating.
We must replace these apps. 2017 was Google's year.
Files is a file manager. It's quick, innovative, and clean. They've given people what they want.
It's easy to organize files, clear space, and clear cache.
I recommend Gallery by Google as a gallery app alternative. It's quick and easy.
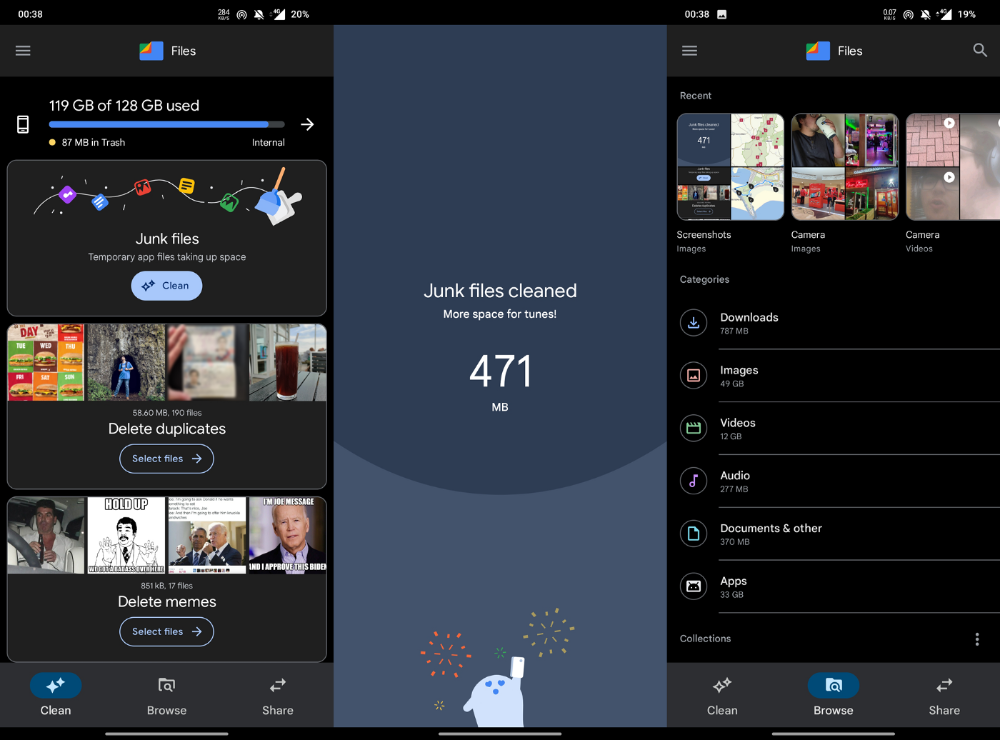
Trainline
App for trains, buses, and coaches.
I've used this app for years. It did the basics well when I first used it.
Since then, it's improved. It's constantly adding features to make traveling easier and less stressful.
Split-ticketing helps me save hundreds a year on train fares. This app is only available in the UK and Europe.
This service doesn't link to a third-party site. Their app handles everything.
Not all train and coach companies use this app. All the big names are there, though.
Here's more on the app.
Battlefield: Mobile
Play Store has 478,000 games. Few can turn my phone into a console.
Call of Duty Mobile and Asphalt 8/9 are examples.
Asphalt's loot boxes and ads make it unplayable. Call of Duty opens with a few ads. Close them to play without hassle.
This game uses all your phone's features to provide a high-quality, seamless experience. If my internet connection is good, I never experience lag or glitches.
The gameplay is energizing and intense, just like on consoles. Sometimes I'm too involved. I've thrown my phone in anger. I'm totally absorbed.
Customizability is my favorite. Since phones have limited screen space, we should only have the buttons we need, placed conveniently.
Size, opacity, and position are modifiable. Adjust audio, graphics, and textures. It's customizable.
This game has been on my phone for three years. It began well and has gotten better. When I think the creators can't do more, they do.
If you play, read my tips for winning a Battle Royale.
Lightroom
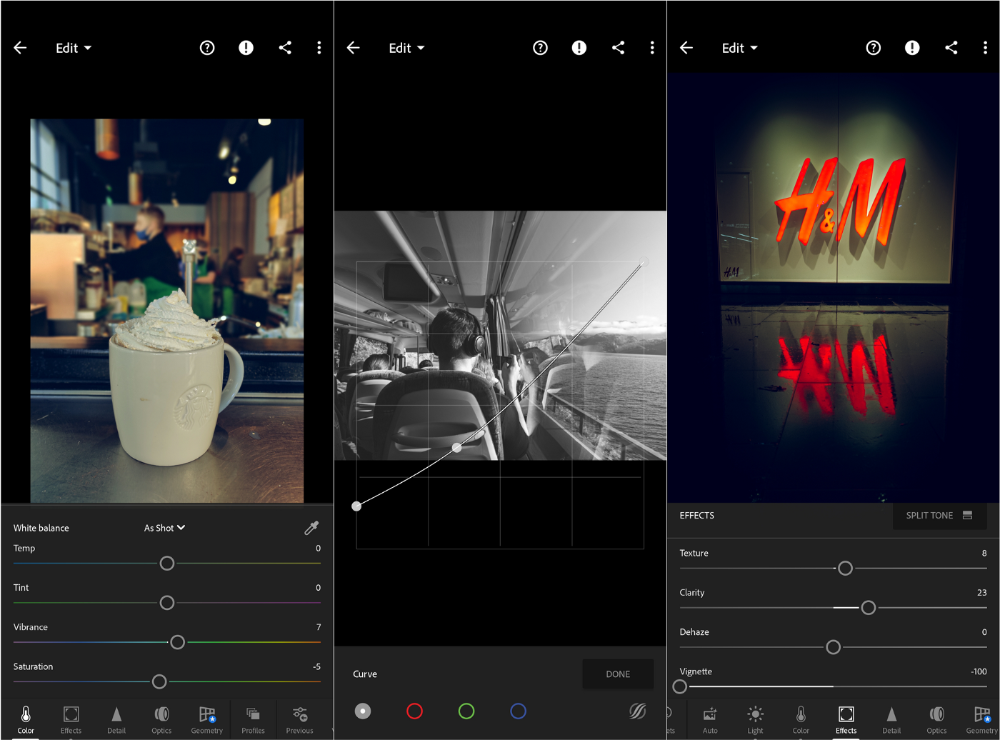
As a photographer, I believe your best camera is on you. The phone.
2017 was a big year for this app. I've tried many photo-editing apps since then. This always wins.
The app is dull. I've never seen better photo editing on a phone.
Adjusting settings and sliders doesn't damage or compress photos. It's detailed.
This is important for phone photos, which are lower quality than professional ones.
Some tools are behind a £4.49/month paywall. Adobe must charge a subscription fee instead of selling licenses. (I'm still bitter about Creative Cloud's price)
Snapseed is my pick. Lightroom is where I do basic editing before moving to Snapseed. Snapseed review:

These apps are great. They cover basic and complex editing needs while traveling.
Final Reflections
I hope you downloaded one of these. Share your favorite apps. These apps are scarce.

Ben "The Hosk" Hosking
3 years ago
The Yellow Cat Test Is Typically Failed by Software Developers.
Believe what you see, what people say

It’s sad that we never get trained to leave assumptions behind. - Sebastian Thrun
Many problems in software development are not because of code but because developers create the wrong software. This isn't rare because software is emergent and most individuals only realize what they want after it's built.
Inquisitive developers who pass the yellow cat test can improve the process.
Carpenters measure twice and cut the wood once. Developers are rarely so careful.
The Yellow Cat Test
Game of Thrones made dragons cool again, so I am reading The Game of Thrones book.
The yellow cat exam is from Syrio Forel, Arya Stark's fencing instructor.
Syrio tells Arya he'll strike left when fencing. He hits her after she dodges left. Arya says “you lied”. Syrio says his words lied, but his eyes and arm told the truth.
Arya learns how Syrio became Bravos' first sword.
“On the day I am speaking of, the first sword was newly dead, and the Sealord sent for me. Many bravos had come to him, and as many had been sent away, none could say why. When I came into his presence, he was seated, and in his lap was a fat yellow cat. He told me that one of his captains had brought the beast to him, from an island beyond the sunrise. ‘Have you ever seen her like?’ he asked of me.
“And to him I said, ‘Each night in the alleys of Braavos I see a thousand like him,’ and the Sealord laughed, and that day I was named the first sword.”
Arya screwed up her face. “I don’t understand.”
Syrio clicked his teeth together. “The cat was an ordinary cat, no more. The others expected a fabulous beast, so that is what they saw. How large it was, they said. It was no larger than any other cat, only fat from indolence, for the Sealord fed it from his own table. What curious small ears, they said. Its ears had been chewed away in kitten fights. And it was plainly a tomcat, yet the Sealord said ‘her,’ and that is what the others saw. Are you hearing?” Reddit discussion.
Development teams should not believe what they are told.
We created an appointment booking system. We thought it was an appointment-booking system. Later, we realized the software's purpose was to book the right people for appointments and discourage the unneeded ones.
The first 3 months of the project had half-correct requirements and software understanding.
Open your eyes
“Open your eyes is all that is needed. The heart lies and the head plays tricks with us, but the eyes see true. Look with your eyes, hear with your ears. Taste with your mouth. Smell with your nose. Feel with your skin. Then comes the thinking afterwards, and in that way, knowing the truth” Syrio Ferel
We must see what exists, not what individuals tell the development team or how developers think the software should work. Initial criteria cover 50/70% and change.
Developers build assumptions problems by assuming how software should work. Developers must quickly explain assumptions.
When a development team's assumptions are inaccurate, they must alter the code, DevOps, documentation, and tests.
It’s always faster and easier to fix requirements before code is written.
First-draft requirements can be based on old software. Development teams must grasp corporate goals and consider needs from many angles.
Testers help rethink requirements. They look at how software requirements shouldn't operate.
Technical features and benefits might misdirect software projects.
The initiatives that focused on technological possibilities developed hard-to-use software that needed extensive rewriting following user testing.
Software development
High-level criteria are different from detailed ones.
The interpretation of words determines their meaning.
Presentations are lofty, upbeat, and prejudiced.
People's perceptions may be unclear, incorrect, or just based on one perspective (half the story)
Developers can be misled by requirements, circumstances, people, plans, diagrams, designs, documentation, and many other things.
Developers receive misinformation, misunderstandings, and wrong assumptions. The development team must avoid building software with erroneous specifications.
Once code and software are written, the development team changes and fixes them.
Developers create software with incomplete information, they need to fill in the blanks to create the complete picture.
Conclusion
Yellow cats are often inaccurate when communicating requirements.
Before writing code, clarify requirements, assumptions, etc.
Everyone will pressure the development team to generate code rapidly, but this will slow down development.
Code changes are harder than requirements.

Waleed Rikab, PhD
3 years ago
The Enablement of Fraud and Misinformation by Generative AI What You Should Understand
Recent investigations have shown that generative AI can boost hackers and misinformation spreaders.

Since its inception in late November 2022, OpenAI's ChatGPT has entertained and assisted many online users in writing, coding, task automation, and linguistic translation. Given this versatility, it is maybe unsurprising but nonetheless regrettable that fraudsters and mis-, dis-, and malinformation (MDM) spreaders are also considering ChatGPT and related AI models to streamline and improve their operations.
Malign actors may benefit from ChatGPT, according to a WithSecure research. ChatGPT promises to elevate unlawful operations across many attack channels. ChatGPT can automate spear phishing attacks that deceive corporate victims into reading emails from trusted parties. Malware, extortion, and illicit fund transfers can result from such access.
ChatGPT's ability to simulate a desired writing style makes spear phishing emails look more genuine, especially for international actors who don't speak English (or other languages like Spanish and French).
This technique could let Russian, North Korean, and Iranian state-backed hackers conduct more convincing social engineering and election intervention in the US. ChatGPT can also create several campaigns and various phony online personas to promote them, making such attacks successful through volume or variation. Additionally, image-generating AI algorithms and other developing techniques can help these efforts deceive potential victims.
Hackers are discussing using ChatGPT to install malware and steal data, according to a Check Point research. Though ChatGPT's scripts are well-known in the cyber security business, they can assist amateur actors with little technical understanding into the field and possibly develop their hacking and social engineering skills through repeated use.
Additionally, ChatGPT's hacking suggestions may change. As a writer recently indicated, ChatGPT's ability to blend textual and code-based writing might be a game-changer, allowing the injection of innocent content that would subsequently turn out to be a malicious script into targeted systems. These new AI-powered writing- and code-generation abilities allow for unique cyber attacks, regardless of viability.
OpenAI fears ChatGPT usage. OpenAI, Georgetown University's Center for Security and Emerging Technology, and Stanford's Internet Observatory wrote a paper on how AI language models could enhance nation state-backed influence operations. As a last resort, the authors consider polluting the internet with radioactive or misleading data to ensure that AI language models produce outputs that other language models can identify as AI-generated. However, the authors of this paper seem unaware that their "solution" might cause much worse MDM difficulties.
Literally False News
The public argument about ChatGPTs content-generation has focused on originality, bias, and academic honesty, but broader global issues are at stake. ChatGPT can influence public opinion, troll individuals, and interfere in local and national elections by creating and automating enormous amounts of social media material for specified audiences.
ChatGPT's capacity to generate textual and code output is crucial. ChatGPT can write Python scripts for social media bots and give diverse content for repeated posts. The tool's sophistication makes it irrelevant to one's language skills, especially English, when writing MDM propaganda.
I ordered ChatGPT to write a news piece in the style of big US publications declaring that Ukraine is on the verge of defeat in its fight against Russia due to corruption, desertion, and exhaustion in its army. I also gave it a fake reporter's byline and an unidentified NATO source's remark. The outcome appears convincing:

Worse, terrible performers can modify this piece to make it more credible. They can edit the general's name or add facts about current wars. Furthermore, such actors can create many versions of this report in different forms and distribute them separately, boosting its impact.
In this example, ChatGPT produced a news story regarding (fictional) greater moviegoer fatality rates:
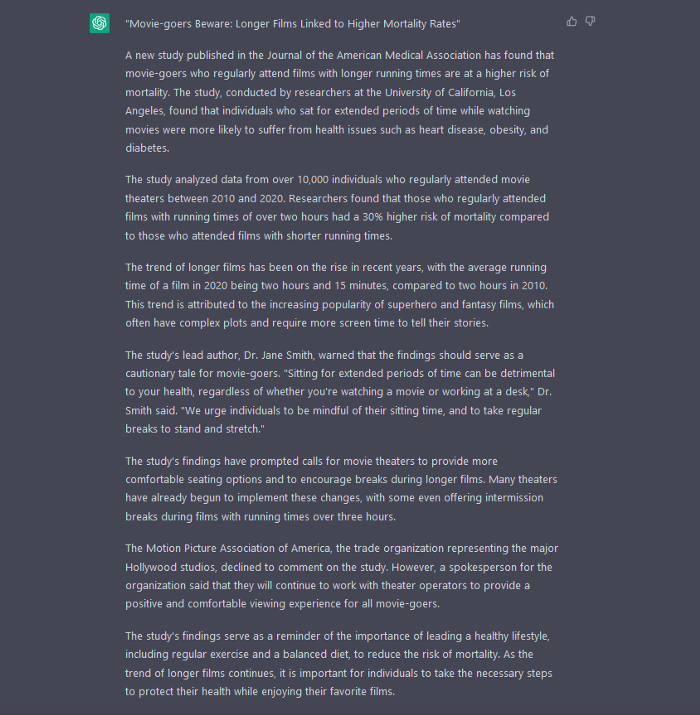
Editing this example makes it more plausible. Dr. Jane Smith, the putative author of the medical report, might be replaced with a real-life medical person or a real victim of this supposed medical hazard.
Can deceptive texts be found? Detecting AI text is behind AI advancements. Minor AI-generated text alterations can upset these technologies.
Some OpenAI individuals have proposed covert methods to watermark AI-generated literature to prevent its abuse. AI models would create information that appears normal to humans but would follow a cryptographic formula that would warn other machines that it was AI-made. However, security experts are cautious since manually altering the content interrupts machine and human detection of AI-generated material.
How to Prepare
Cyber security and IT workers can research and use generative AI models to fight spear fishing and extortion. Governments may also launch MDM-defence projects.
In election cycles and global crises, regular people may be the most vulnerable to AI-produced deceit. Until regulation or subsequent technical advances, individuals must recognize exposure to AI-generated fraud, dating scams, other MDM activities.
A three-step verification method of new material in suspicious emails or social media posts can help identify AI content and manipulation. This three-step approach asks about the information's distribution platform (is it reliable? ), author (is the reader familiar with them? ), and plausibility given one's prior knowledge of the topic.
Consider a report by a trusted journalist that makes shocking statements in their typical manner. AI-powered fake news may be released on an unexpected platform, such as a newly created Facebook profile. However, if it links to a known media source, it is more likely to be real.
Though hard and subjective, this verification method may be the only barrier against manipulation for now.
AI language models:
How to Recognize an AI-Generated Article ChatGPT, the popular AI-powered chatbot, can and likely does generate medium.com-style articles.
AI-Generated Text Detectors Fail. Do This. Online tools claim to detect ChatGPT output. Even with superior programming, I tested some of these tools. pub
Why Original Writers Matter Despite AI Language Models Creative writers may never be threatened by AI language models.
You might also like

Yogesh Rawal
3 years ago
Blockchain to solve growing privacy challenges
Most online activity is now public. Businesses collect, store, and use our personal data to improve sales and services.
In 2014, Uber executives and employees were accused of spying on customers using tools like maps. Another incident raised concerns about the use of ‘FaceApp'. The app was created by a small Russian company, and the photos can be used in unexpected ways. The Cambridge Analytica scandal exposed serious privacy issues. The whole incident raised questions about how governments and businesses should handle data. Modern technologies and practices also make it easier to link data to people.
As a result, governments and regulators have taken steps to protect user data. The General Data Protection Regulation (GDPR) was introduced by the EU to address data privacy issues. The law governs how businesses collect and process user data. The Data Protection Bill in India and the General Data Protection Law in Brazil are similar.
Despite the impact these regulations have made on data practices, a lot of distance is yet to cover.
Blockchain's solution
Blockchain may be able to address growing data privacy concerns. The technology protects our personal data by providing security and anonymity. The blockchain uses random strings of numbers called public and private keys to maintain privacy. These keys allow a person to be identified without revealing their identity. Blockchain may be able to ensure data privacy and security in this way. Let's dig deeper.
Financial transactions
Online payments require third-party services like PayPal or Google Pay. Using blockchain can eliminate the need to trust third parties. Users can send payments between peers using their public and private keys without providing personal information to a third-party application. Blockchain will also secure financial data.
Healthcare data
Blockchain technology can give patients more control over their data. There are benefits to doing so. Once the data is recorded on the ledger, patients can keep it secure and only allow authorized access. They can also only give the healthcare provider part of the information needed.
The major challenge
We tried to figure out how blockchain could help solve the growing data privacy issues. However, using blockchain to address privacy concerns has significant drawbacks. Blockchain is not designed for data privacy. A ‘distributed' ledger will be used to store the data. Another issue is the immutability of blockchain. Data entered into the ledger cannot be changed or deleted. It will be impossible to remove personal data from the ledger even if desired.
MIT's Enigma Project aims to solve this. Enigma's ‘Secret Network' allows nodes to process data without seeing it. Decentralized applications can use Secret Network to use encrypted data without revealing it.
Another startup, Oasis Labs, uses blockchain to address data privacy issues. They are working on a system that will allow businesses to protect their customers' data.
Conclusion
Blockchain technology is already being used. Several governments use blockchain to eliminate centralized servers and improve data security. In this information age, it is vital to safeguard our data. How blockchain can help us in this matter is still unknown as the world explores the technology.

Chris Moyse
3 years ago
Sony and LEGO raise $2 billion for Epic Games' metaverse
‘Kid-friendly’ project holds $32 billion valuation
Epic Games announced today that it has raised $2 billion USD from Sony Group Corporation and KIRKBI (holding company of The LEGO Group). Both companies contributed $1 billion to Epic Games' upcoming ‘metaverse' project.
“We need partners who share our vision as we reimagine entertainment and play. Our partnership with Sony and KIRKBI has found this,” said Epic Games CEO Tim Sweeney. A new metaverse will be built where players can have fun with friends and brands create creative and immersive experiences, as well as creators thrive.
Last week, LEGO and Epic Games announced their plans to create a family-friendly metaverse where kids can play, interact, and create in digital environments. The service's users' safety and security will be prioritized.
With this new round of funding, Epic Games' project is now valued at $32 billion.
“Epic Games is known for empowering creators large and small,” said KIRKBI CEO Sren Thorup Srensen. “We invest in trends that we believe will impact the world we and our children will live in. We are pleased to invest in Epic Games to support their continued growth journey, with a long-term focus on the future metaverse.”
Epic Games is expected to unveil its metaverse plans later this year, including its name, details, services, and release date.

Hasan AboulHasan
3 years ago
High attachment products can help you earn money automatically.

Affiliate marketing is a popular online moneymaker. You promote others' products and get commissions. Affiliate marketing requires constant product promotion.
Affiliate marketing can be profitable even without much promotion. Yes, this is Autopilot Money.
How to Pick an Affiliate Program to Generate Income Autonomously
Autopilot moneymaking requires a recurring affiliate marketing program.
Finding the best product and testing it takes a lot of time and effort.
Here are three ways to choose the best service or product to promote:
Find a good attachment-rate product or service.
When choosing a product, ask if you can easily switch to another service. Attachment rate is how much people like a product.
Higher attachment rates mean better Autopilot products.
Consider promoting GetResponse. It's a 33% recurring commission email marketing tool. This means you get 33% of the customer's plan as long as he pays.
GetResponse has a high attachment rate because it's hard to leave and start over with another tool.
2. Pick a good or service with a lot of affiliate assets.
Check if a program has affiliate assets or creatives before joining.
Images and banners to promote the product in your business.
They save time; I look for promotional creatives. Creatives or affiliate assets are website banners or images. This reduces design time.
3. Select a service or item that consumers already adore.
New products are hard to sell. Choosing a trusted company's popular product or service is helpful.
As a beginner, let people buy a product they already love.
Online entrepreneurs and digital marketers love Systeme.io. It offers tools for creating pages, email marketing, funnels, and more. This product guarantees a high ROI.
Make the product known!
Affiliate marketers struggle to get traffic. Using affiliate marketing to make money is easier than you think if you have a solid marketing strategy.
Your plan should include:
1- Publish affiliate-related blog posts and SEO-optimize them
2- Sending new visitors product-related emails
3- Create a product resource page.
4-Review products
5-Make YouTube videos with links in the description.
6- Answering FAQs about your products and services on your blog and Quora.
7- Create an eCourse on how to use this product.
8- Adding Affiliate Banners to Your Website.
With these tips, you can promote your products and make money on autopilot.