




More on Technology

Enrique Dans
3 years ago
You may not know about The Merge, yet it could change society

Ethereum is the second-largest cryptocurrency. The Merge, a mid-September event that will convert Ethereum's consensus process from proof-of-work to proof-of-stake if all goes according to plan, will be a game changer.
Why is Ethereum ditching proof-of-work? Because it can. We're talking about a fully functioning, open-source ecosystem with a capacity for evolution that other cryptocurrencies lack, a change that would allow it to scale up its performance from 15 transactions per second to 100,000 as its blockchain is used for more and more things. It would reduce its energy consumption by 99.95%. Vitalik Buterin, the system's founder, would play a less active role due to decentralization, and miners, who validated transactions through proof of work, would be far less important.
Why has this conversion taken so long and been so cautious? Because it involves modifying a core process while it's running to boost its performance. It requires running the new mechanism in test chains on an ever-increasing scale, assessing participant reactions, and checking for issues or restrictions. The last big test was in early June and was successful. All that's left is to converge the mechanism with the Ethereum blockchain to conclude the switch.
What's stopping Bitcoin, the leader in market capitalization and the cryptocurrency that began blockchain's appeal, from doing the same? Satoshi Nakamoto, whoever he or she is, departed from public life long ago, therefore there's no community leadership. Changing it takes a level of consensus that is impossible to achieve without strong leadership, which is why Bitcoin's evolution has been sluggish and conservative, with few modifications.
Secondly, The Merge will balance the consensus mechanism (proof-of-work or proof-of-stake) and the system decentralization or centralization. Proof-of-work prevents double-spending, thus validators must buy hardware. The system works, but it requires a lot of electricity and, as it scales up, tends to re-centralize as validators acquire more hardware and the entire network activity gets focused in a few nodes. Larger operations save more money, which increases profitability and market share. This evolution runs opposed to the concept of decentralization, and some anticipate that any system that uses proof of work as a consensus mechanism will evolve towards centralization, with fewer large firms able to invest in efficient network nodes.
Yet radical bitcoin enthusiasts share an opposite argument. In proof-of-stake, transaction validators put their funds at stake to attest that transactions are valid. The algorithm chooses who validates each transaction, giving more possibilities to nodes that put more coins at stake, which could open the door to centralization and government control.
In both cases, we're talking about long-term changes, but Bitcoin's proof-of-work has been evolving longer and seems to confirm those fears, while proof-of-stake is only employed in coins with a minuscule volume compared to Ethereum and has no predictive value.
As of mid-September, we will have two significant cryptocurrencies, each with a different consensus mechanisms and equally different characteristics: one is intrinsically conservative and used only for economic transactions, while the other has been evolving in open source mode, and can be used for other types of assets, smart contracts, or decentralized finance systems. Some even see it as the foundation of Web3.
Many things could change before September 15, but The Merge is likely to be a turning point. We'll have to follow this closely.

Jano le Roux
3 years ago
Apple Quietly Introduces A Revolutionary Savings Account That Kills Banks
Would you abandon your bank for Apple?

Banks are struggling.
not as a result of inflation
not due to the economic downturn.
not due to the conflict in Ukraine.
But because they’re underestimating Apple.
Slowly but surely, Apple is looking more like a bank.
An easy new savings account like Apple
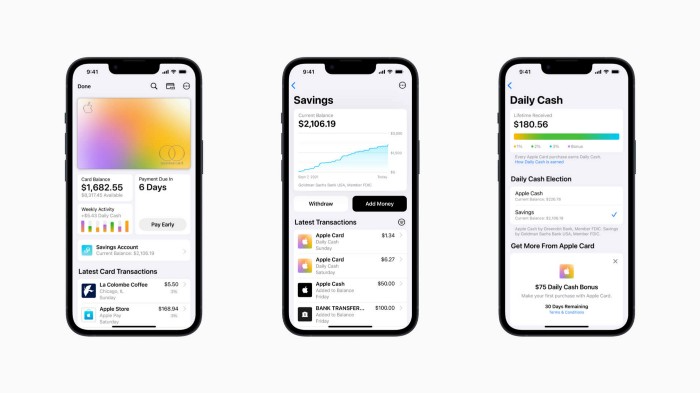
Apple has a new savings account.
Apple says Apple Card users may set up and manage savings straight in Wallet.
No more charges
Colorfully high yields
With no minimum balance
No minimal down payments
Most consumer-facing banks will have to match Apple's offer or suffer disruption.
Users may set it up from their iPhones without traveling to a bank or filling out paperwork.
It’s built into the iPhone in your pocket.
So now more waiting for slow approval processes.
Once the savings account is set up, Apple will automatically transfer all future Daily Cash into it. Users may also add these cash to an Apple Cash card in their Apple Wallet app and adjust where Daily Cash is paid at any time.
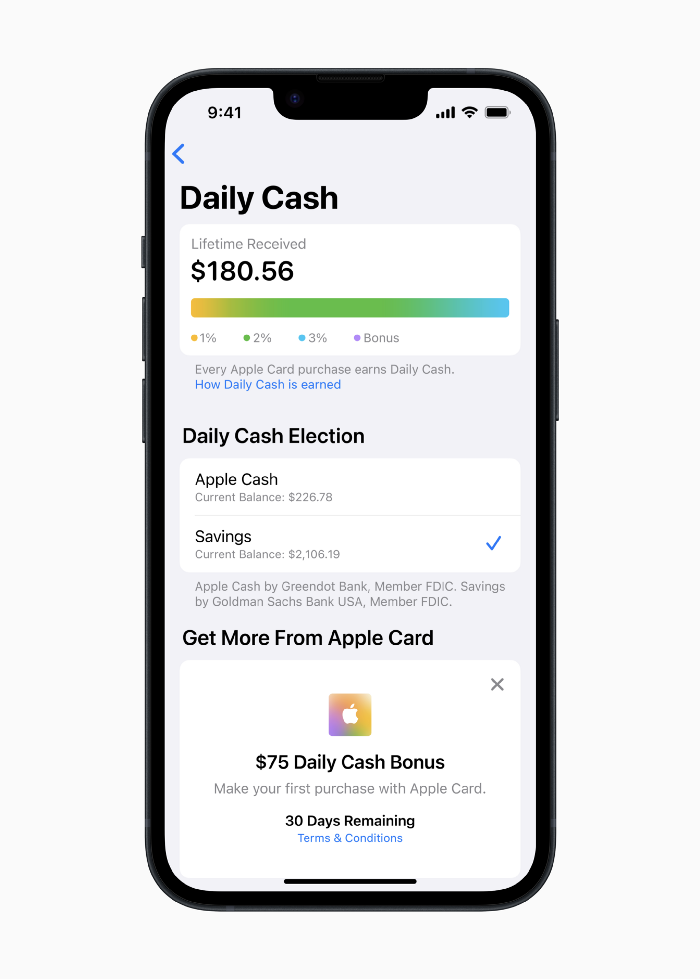
Apple Pay and Apple Wallet VP Jennifer Bailey:
Savings enables Apple Card users to grow their Daily Cash rewards over time, while also saving for the future.
Bailey says Savings adds value to Apple Card's Daily Cash benefit and offers another easy-to-use tool to help people lead healthier financial lives.
Transfer money from a linked bank account or Apple Cash to a Savings account. Users can withdraw monies to a connected bank account or Apple Cash card without costs.
Once set up, Apple Card customers can track their earnings via Wallet's Savings dashboard. This dashboard shows their account balance and interest.
This product targets younger people as the easiest way to start a savings account on the iPhone.
Why would a Gen Z account holder travel to the bank if their iPhone could be their bank?
Using this concept, Apple will transform the way we think about banking by 2030.
Two other nightmares keep bankers awake at night
Apple revealed two new features in early 2022 that banks and payment gateways hated.
Tap to Pay with Apple
Late Apple Pay
They startled the industry.
Tap To Pay converts iPhones into mobile POS card readers. Apple Pay Later is pushing the BNPL business in a consumer-friendly direction, hopefully ending dodgy lending practices.
Tap to Pay with Apple
iPhone POS

Millions of US merchants, from tiny shops to huge establishments, will be able to accept Apple Pay, contactless credit and debit cards, and other digital wallets with a tap.
No hardware or payment terminal is needed.
Revolutionary!
Stripe has previously launched this feature.
Tap to Pay on iPhone will provide companies with a secure, private, and quick option to take contactless payments and unleash new checkout experiences, said Bailey.
Apple's solution is ingenious. Brilliant!
Bailey says that payment platforms, app developers, and payment networks are making it easier than ever for businesses of all sizes to accept contactless payments and thrive.
I admire that Apple is offering this up to third-party services instead of closing off other functionalities.
Slow POS terminals, farewell.
Late Apple Pay
Pay Apple later.
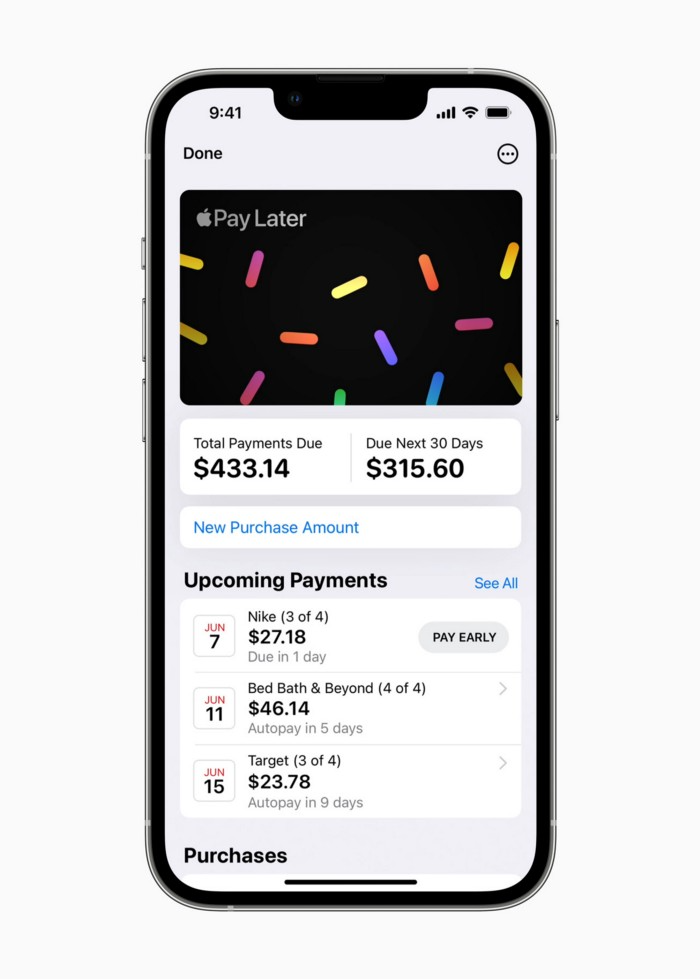
Apple Pay Later enables US consumers split Apple Pay purchases into four equal payments over six weeks with no interest or fees.
The Apple ecosystem integration makes this BNPL scheme unique. Nonstick. No dumb forms.
Frictionless.
Just double-tap the button.
Apple Pay Later was designed with users' financial well-being in mind. Apple makes it easy to use, track, and pay back Apple Pay Later from Wallet.
Apple Pay Later can be signed up in Wallet or when using Apple Pay. Apple Pay Later can be used online or in an app that takes Apple Pay and leverages the Mastercard network.
Apple Pay Order Tracking helps consumers access detailed receipts and order tracking in Wallet for Apple Pay purchases at participating stores.
Bad BNPL suppliers, goodbye.
Most bankers will be caught in Apple's eye playing mini golf in high-rise offices.
The big problem:
Banks still think about features and big numbers just like other smartphone makers did not too long ago.
Apple thinks about effortlessness, seamlessness, and frictionlessness that just work through integrated hardware and software.
Let me know what you think Apple’s next power moves in the banking industry could be.

Christianlauer
3 years ago
Looker Studio Pro is now generally available, according to Google.
Great News about the new Google Business Intelligence Solution

Google has renamed Data Studio to Looker Studio and Looker Studio Pro.
Now, Google releases Looker Studio Pro. Similar to the move from Data Studio to Looker Studio, Looker Studio Pro is basically what Looker was previously, but both solutions will merge. Google says the Pro edition will acquire new enterprise management features, team collaboration capabilities, and SLAs.
![Dashboard Example in Looker Studio Pro — Image Source: Google[2]](https://storage.googleapis.com/int3grity/posts/m9yb4IqJCm7D/images/ZuJudlWT6GUeTKKNVduA5)
In addition to Google's announcements and sales methods, additional features include:
Looker Studio assets can now have organizational ownership. Customers can link Looker Studio to a Google Cloud project and migrate existing assets once. This provides:
Your users' created Looker Studio assets are all kept in a Google Cloud project.
When the users who own assets leave your organization, the assets won't be removed.
Using IAM, you may provide each Looker Studio asset in your company project-level permissions.
Other Cloud services can access Looker Studio assets that are owned by a Google Cloud project.
Looker Studio Pro clients may now manage report and data source access at scale using team workspaces.
Google announcing these features for the pro version is fascinating. Both products will likely converge, but Google may only release many features in the premium version in the future. Microsoft with Power BI and its free and premium variants already achieves this.
Sources and Further Readings
Google, Release Notes (2022)
Google, Looker (2022)
You might also like

Jeff John Roberts
3 years ago
Jack Dorsey and Jay-Z Launch 'Bitcoin Academy' in Brooklyn rapper's home
The new Bitcoin Academy will teach Jay-Marcy Z's Houses neighbors "What is Cryptocurrency."
Jay-Z grew up in Brooklyn's Marcy Houses. The rapper and Block CEO Jack Dorsey are giving back to his hometown by creating the Bitcoin Academy.
The Bitcoin Academy will offer online and in-person classes, including "What is Money?" and "What is Blockchain?"
The program will provide participants with a mobile hotspot and a small amount of Bitcoin for hands-on learning.
Students will receive dinner and two evenings of instruction until early September. The Shawn Carter Foundation will help with on-the-ground instruction.
Jay-Z and Dorsey announced the program Thursday morning. It will begin at Marcy Houses but may be expanded.
Crypto Blockchain Plug and Black Bitcoin Billionaire, which has received a grant from Block, will teach the classes.
Jay-Z, Dorsey reunite
Jay-Z and Dorsey have previously worked together to promote a Bitcoin and crypto-based future.
In 2021, Dorsey's Block (then Square) acquired the rapper's streaming music service Tidal, which they propose using for NFT distribution.
Dorsey and Jay-Z launched an endowment in 2021 to fund Bitcoin development in Africa and India.
Dorsey is funding the new Bitcoin Academy out of his own pocket (as is Jay-Z), but he's also pushed crypto-related charitable endeavors at Block, including a $5 million fund backed by corporate Bitcoin interest.
This post is a summary. Read full article here

Athirah Syamimi
3 years ago
Here's How I Built A Business Offering Unlimited Design Services in Just One Weekend.

Weekend project: limitless design service. It was fun to see whether I could start a business quickly.
I use no-code apps to save time and resources.
TL;DR I started a business utilizing EditorX for my website, Notion for client project management, and a few favors to finish my portfolio.
First step: research (Day 1)
I got this concept from a Kimp Instagram ad. The Minimalist Hustler Daily newsletter mentioned a similar and cheaper service (Graphically).
I Googled other unlimited design companies. Many provide different costs and services. Some supplied solely graphic design, web development, or copywriting.
Step 2: Brainstorming (Day 1)
I did something simple.
What benefits and services to provide
Price to charge
Since it's a one-person performance (for now), I'm focusing on graphic design. I can charge less.
So I don't overwhelm myself and can accommodate budget-conscious clientele.
Step 3: Construction (Day 1 & 2)
This project includes a management tool, a website, and a team procedure.
I built a project management tool and flow first. Once I had the flow and a Notion board, I tested it with design volunteers. They fake-designed while I built the website.
Tool for Project Management
I modified a Notion template. My goal is to keep clients and designers happy.
Team Approach
My sister, my partner, and I kept this business lean. I tweaked the Notion board to make the process smooth. By the end of Sunday, I’d say it’s perfect!
Website
I created the website after they finished the fake design demands. EditorX's drag-and-drop builder attracted me. I didn't need to learn code, and there are templates.
I used a template wireframe.
This project's hardest aspect is developing the site. It's my first time using EditorX and I'm no developer.
People answer all your inquiries in a large community forum.
As a first-time user developing a site in two days, I think I performed OK. Here's the site for feedback.

4th step: testing (Day 2)
Testing is frustrating because it works or doesn't. My testing day was split in two.
testing the workflow from payment to onboarding to the website
the demand being tested
It's working so far. If someone gets the trial, they can request design work.
I've gotten a couple of inquiries about demand. I’ll be working with them as a start.
Completion
Finally! I built my side project in one weekend. It's too early to tell if this is successful. I liked that I didn't squander months of resources testing out an idea.

Jayden Levitt
3 years ago
The country of El Salvador's Bitcoin-obsessed president lost $61.6 million.
It’s only a loss if you sell, right?

Nayib Bukele proclaimed himself “the world’s coolest dictator”.
His jokes aren't clear.
El Salvador's 43rd president self-proclaimed “CEO of El Salvador” couldn't be less presidential.
His thin jeans, aviator sunglasses, and baseball caps like a cartel lord.
He's popular, though.
Bukele won 53% of the vote by fighting violent crime and opposition party corruption.
El Salvador's 6.4 million inhabitants are riding the cryptocurrency volatility wave.
They were powerless.
Their autocratic leader, a former Yamaha Motors salesperson and Bitcoin believer, wants to help 70% unbanked locals.
He intended to give the citizens a way to save money and cut the country's $200 million remittance cost.
Transfer and deposit costs.
This makes logical sense when the president’s theatrics don’t blind you.
El Salvador's Bukele revealed plans to make bitcoin legal tender.
Remittances total $5.9 billion (23%) of the country's expenses.
Anything that reduces costs could boost the economy.
The country’s unbanked population is staggering. Here’s the data by % of people who either have a bank account (Blue) or a mobile money account (Black).
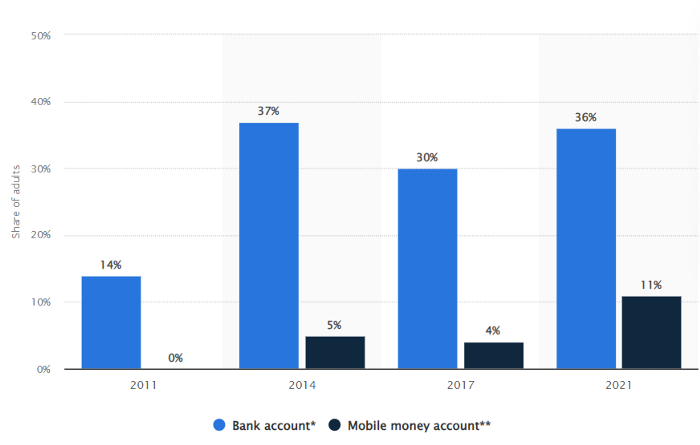
According to Bukele, 46% of the population has downloaded the Chivo Bitcoin Wallet.
In 2021, 36% of El Salvadorans had bank accounts.
Large rural countries like Kenya seem to have resolved their unbanked dilemma.
An economy surfaced where village locals would sell, trade and store network minutes and data as a store of value.
Kenyan phone networks realized unbanked people needed a safe way to accumulate wealth and have an emergency fund.
96% of Kenyans utilize M-PESA, which doesn't require a bank account.
The software involves human agents who hang out with cash and a phone.
These people are like ATMs.
You offer them cash to deposit money in your mobile money account or withdraw cash.
In a country with a faulty banking system, cash availability and a safe place to deposit it are important.
William Jack and Tavneet Suri found that M-PESA brought 194,000 Kenyan households out of poverty by making transactions cheaper and creating a safe store of value.
Mobile money, a service that allows monetary value to be stored on a mobile phone and sent to other users via text messages, has been adopted by most Kenyan households. We estimate that access to the Kenyan mobile money system M-PESA increased per capita consumption levels and lifted 194,000 households, or 2% of Kenyan households, out of poverty.
The impacts, which are more pronounced for female-headed households, appear to be driven by changes in financial behaviour — in particular, increased financial resilience and saving. Mobile money has therefore increased the efficiency of the allocation of consumption over time while allowing a more efficient allocation of labour, resulting in a meaningful reduction of poverty in Kenya.
Currently, El Salvador has 2,301 Bitcoin.
At publication, it's worth $44 million. That remains 41% of Bukele's original $105.6 million.
Unknown if the country has sold Bitcoin, but Bukeles keeps purchasing the dip.
It's still falling.

This might be a fantastic move for the impoverished country over the next five years, if they can live economically till Bitcoin's price recovers.
The evidence demonstrates that a store of value pulls individuals out of poverty, but others say Bitcoin is premature.
You may regard it as an aggressive endeavor to front run the next wave of adoption, offering El Salvador a financial upside.