


More on NFTs & Art

Jayden Levitt
3 years ago
How to Explain NFTs to Your Grandmother, in Simple Terms

In simple terms, you probably don’t.
But try. Grandma didn't grow up with Facebook, but she eventually joined.
Perhaps the fear of being isolated outweighed the discomfort of learning the technology.
Grandmas are Facebook likers, sharers, and commenters.
There’s no stopping her.
Not even NFTs. Web3 is currently very complex.
It's difficult to explain what NFTs are, how they work, and why we might use them.
Three explanations.
1. Everything will be ours to own, both physically and digitally.
Why own something you can't touch? What's the point?
Blockchain technology proves digital ownership.
Untouchables need ownership proof. What?
Digital assets reduce friction, save time, and are better for the environment than physical goods.
Many valuable things are intangible. Feeling like your favorite brands. You'll pay obscene prices for clothing that costs pennies.
Secondly, NFTs Are Contracts. Agreements Have Value.
Blockchain technology will replace all contracts and intermediaries.
Every insurance contract, deed, marriage certificate, work contract, plane ticket, concert ticket, or sports event is likely an NFT.
We all have public wallets, like Grandma's Facebook page.
3. Your NFT Purchases Will Be Visible To Everyone.
Everyone can see your public wallet. What you buy says more about you than what you post online.
NFTs issued double as marketing collateral when seen on social media.
While I doubt Grandma knows who Snoop Dog is, imagine him or another famous person holding your NFT in his public wallet and the attention that could bring to you, your company, or brand.
This Technical Section Is For You
The NFT is a contract; its founders can add value through access, events, tuition, and possibly royalties.
Imagine Elon Musk releasing an NFT to his network. Or yearly business consultations for three years.
Christ-alive.
It's worth millions.
These determine their value.
No unsuspecting schmuck willing to buy your hot potato at zero. That's the trend, though.
Overpriced NFTs for low-effort projects created a bubble that has burst.
During a market bubble, you can make money by buying overvalued assets and selling them later for a profit, according to the Greater Fool Theory.
People are struggling. Some are ruined by collateralized loans and the gold rush.
Finances are ruined.
It's uncomfortable.
The same happened in 2018, during the ICO crash or in 1999/2000 when the dot com bubble burst. But the underlying technology hasn’t gone away.
Dmytro Spilka
3 years ago
Why NFTs Have a Bright Future Away from Collectible Art After Punks and Apes

After a crazy second half of 2021 and significant trade volumes into 2022, the market for NFT artworks like Bored Ape Yacht Club, CryptoPunks, and Pudgy Penguins has begun a sharp collapse as market downturns hit token values.
DappRadar data shows NFT monthly sales have fallen below $1 billion since June 2021. OpenSea, the world's largest NFT exchange, has seen sales volume decline 75% since May and is trading like July 2021.
Prices of popular non-fungible tokens have also decreased. Bored Ape Yacht Club (BAYC) has witnessed volume and sales drop 63% and 15%, respectively, in the past month.
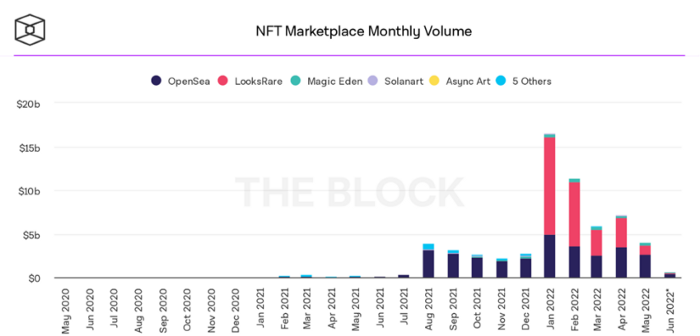
BeInCrypto analysis shows market decline. May 2022 cryptocurrency marketplace volume was $4 billion, according to a news platform. This is a sharp drop from April's $7.18 billion.
OpenSea, a big marketplace, contributed $2.6 billion, while LooksRare, Magic Eden, and Solanart also contributed.
NFT markets are digital platforms for buying and selling tokens, similar stock trading platforms. Although some of the world's largest exchanges offer NFT wallets, most users store their NFTs on their favorite marketplaces.
In January 2022, overall NFT sales volume was $16.57 billion, with LooksRare contributing $11.1 billion. May 2022's volume was $12.57 less than January, a 75% drop, and June's is expected to be considerably smaller.
A World Based on Utility
Despite declines in NFT trading volumes, not all investors are negative on NFTs. Although there are uncertainties about the sustainability of NFT-based art collections, there are fewer reservations about utility-based tokens and their significance in technology's future.
In June, business CEO Christof Straub said NFTs may help artists monetize unreleased content, resuscitate catalogs, establish deeper fan connections, and make processes more efficient through technology.
We all know NFTs can't be JPEGs. Straub noted that NFT music rights can offer more equitable rewards to musicians.
Music NFTs are here to stay if they have real value, solve real problems, are trusted and lawful, and have fair and sustainable business models.
NFTs can transform numerous industries, including music. Market opinion is shifting towards tokens with more utility than the social media artworks we're used to seeing.
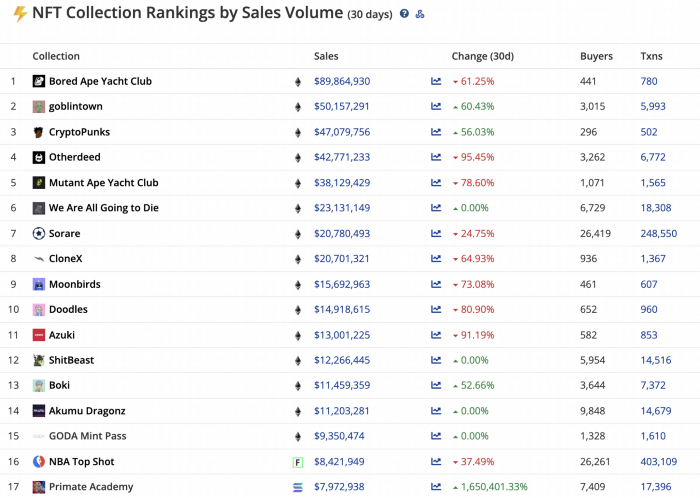
While the major NFT names remain dominant in terms of volume, new utility-based initiatives are emerging as top 20 collections.
Otherdeed, Sorare, and NBA Top Shot are NFT-based games that rank above Bored Ape Yacht Club and Cryptopunks.
Users can switch video NFTs of basketball players in NBA Top Shot. Similar efforts are emerging in the non-fungible landscape.
Sorare shows how NFTs can support a new way of playing fantasy football, where participants buy and swap trading cards to create a 5-player team that wins rewards based on real-life performances.
Sorare raised 579.7 million in one of Europe's largest Series B financing deals in September 2021. Recently, the platform revealed plans to expand into Major League Baseball.
Strong growth indications suggest a promising future for NFTs. The value of art-based collections like BAYC and CryptoPunks may be questioned as markets become diluted by new limited collections, but the potential for NFTs to become intrinsically linked to tangible utility like online gaming, music and art, and even corporate reward schemes shows the industry has a bright future.

Amelia Winger-Bearskin
3 years ago
Hate NFTs? I must break some awful news to you...
If you think NFTs are awful, check out the art market.
The fervor around NFTs has subsided in recent months due to the crypto market crash and the media's short attention span. They were all anyone could talk about earlier this spring. Last semester, when passions were high and field luminaries were discussing "slurp juices," I asked my students and students from over 20 other universities what they thought of NFTs.
According to many, NFTs were either tasteless pyramid schemes or a new way for artists to make money. NFTs contributed to the climate crisis and harmed the environment, but so did air travel, fast fashion, and smartphones. Some students complained that NFTs were cheap, tasteless, algorithmically generated schlock, but others asked how this was different from other art.

I'm not sure what I expected, but the intensity of students' reactions surprised me. They had strong, emotional opinions about a technology I'd always considered administrative. NFTs address ownership and accounting, like most crypto/blockchain projects.
Art markets can be irrational, arbitrary, and subject to the same scams and schemes as any market. And maybe a few shenanigans that are unique to the art world.
The Fairness Question
Fairness, a deflating moral currency, was the general sentiment (the less of it in circulation, the more ardently we clamor for it.) These students, almost all of whom are artists, complained to the mismatch between the quality of the work in some notable NFT collections and the excessive amounts these items were fetching on the market. They can sketch a Bored Ape or Lazy Lion in their sleep. Why should they buy ramen with school loans while certain swindlers get rich?

I understand students. Art markets are unjust. They can be irrational, arbitrary, and governed by chance and circumstance, like any market. And art-world shenanigans.
Almost every mainstream critique leveled against NFTs applies just as easily to art markets
Over 50% of artworks in circulation are fake, say experts. Sincere art collectors and institutions are upset by the prevalence of fake goods on the market. Not everyone. Wealthy people and companies use art as investments. They can use cultural institutions like museums and galleries to increase the value of inherited art collections. People sometimes buy artworks and use family ties or connections to museums or other cultural taste-makers to hype the work in their collection, driving up the price and allowing them to sell for a profit. Money launderers can disguise capital flows by using market whims, hype, and fluctuating asset prices.
Almost every mainstream critique leveled against NFTs applies just as easily to art markets.
Art has always been this way. Edward Kienholz's 1989 print series satirized art markets. He stamped 395 identical pieces of paper from $1 to $395. Each piece was initially priced as indicated. Kienholz was joking about a strange feature of art markets: once the last print in a series sells for $395, all previous works are worth at least that much. The entire series is valued at its highest auction price. I don't know what a Kienholz print sells for today (inquire with the gallery), but it's more than $395.
I love Lee Lozano's 1969 "Real Money Piece." Lozano put cash in various denominations in a jar in her apartment and gave it to visitors. She wrote, "Offer guests coffee, diet pepsi, bourbon, half-and-half, ice water, grass, and money." "Offer real money as candy."
Lee Lozano kept track of who she gave money to, how much they took, if any, and how they reacted to the offer of free money without explanation. Diverse reactions. Some found it funny, others found it strange, and others didn't care. Lozano rarely says:
Apr 17 Keith Sonnier refused, later screws lid very tightly back on. Apr 27 Kaltenbach takes all the money out of the jar when I offer it, examines all the money & puts it all back in jar. Says he doesn’t need money now. Apr 28 David Parson refused, laughing. May 1 Warren C. Ingersoll refused. He got very upset about my “attitude towards money.” May 4 Keith Sonnier refused, but said he would take money if he needed it which he might in the near future. May 7 Dick Anderson barely glances at the money when I stick it under his nose and says “Oh no thanks, I intend to earn it on my own.” May 8 Billy Bryant Copley didn’t take any but then it was sort of spoiled because I had told him about this piece on the phone & he had time to think about it he said.
Smart Contracts (smart as in fair, not smart as in Blockchain)
Cornell University's Cheryl Finley has done a lot of research on secondary art markets. I first learned about her research when I met her at the University of Florida's Harn Museum, where she spoke about smart contracts (smart as in fair, not smart as in Blockchain) and new protocols that could help artists who are often left out of the economic benefits of their own work, including women and women of color.

Her talk included findings from her ArtNet op-ed with Lauren van Haaften-Schick, Christian Reeder, and Amy Whitaker.
NFTs allow us to think about and hack on formal contractual relationships outside a system of laws that is currently not set up to service our community.
The ArtNet article The Recent Sale of Amy Sherald's ‘Welfare Queen' Symbolizes the Urgent Need for Resale Royalties and Economic Equity for Artists discussed Sherald's 2012 portrait of a regal woman in a purple dress wearing a sparkling crown and elegant set of pearls against a vibrant red background.
Amy Sherald sold "Welfare Queen" to Princeton professor Imani Perry. Sherald agreed to a payment plan to accommodate Perry's budget.
Amy Sherald rose to fame for her 2016 portrait of Michelle Obama and her full-length portrait of Breonna Taylor, one of the most famous works of the past decade.
As is common, Sherald's rising star drove up the price of her earlier works. Perry's "Welfare Queen" sold for $3.9 million in 2021.

Imani Perry's early investment paid off big-time. Amy Sherald, whose work directly increased the painting's value and who was on an artist's shoestring budget when she agreed to sell "Welfare Queen" in 2012, did not see any of the 2021 auction money. Perry and the auction house got that money.
Sherald sold her Breonna Taylor portrait to the Smithsonian and Louisville's Speed Art Museum to fund a $1 million scholarship. This is a great example of what an artist can do for the community if they can amass wealth through their work.
NFTs haven't solved all of the art market's problems — fakes, money laundering, market manipulation — but they didn't create them. Blockchain and NFTs are credited with making these issues more transparent. More ideas emerge daily about what a smart contract should do for artists.
NFTs are a copyright solution. They allow us to hack formal contractual relationships outside a law system that doesn't serve our community.
Amy Sherald shows the good smart contracts can do (as in, well-considered, self-determined contracts, not necessarily blockchain contracts.) Giving back to our community, deciding where and how our work can be sold or displayed, and ensuring artists share in the equity of our work and the economy our labor creates.

You might also like

Katrine Tjoelsen
3 years ago
8 Communication Hacks I Use as a Young Employee
Learn these subtle cues to gain influence.

Hate being ignored?
As a 24-year-old, I struggled at work. Attention-getting tips How to avoid being judged by my size, gender, and lack of wrinkles or gray hair?
I've learned seniority hacks. Influence. Within two years as a product manager, I led a team. I'm a Stanford MBA student.
These communication hacks can make you look senior and influential.
1. Slowly speak
We speak quickly because we're afraid of being interrupted.
When I doubt my ideas, I speak quickly. How can we slow down? Jamie Chapman says speaking slowly saps our energy.
Chapman suggests emphasizing certain words and pausing.
2. Interrupted? Stop the stopper
Someone interrupt your speech?
Don't wait. "May I finish?" No pause needed. Stop interrupting. I first tried this in Leadership Laboratory at Stanford. How quickly I gained influence amazed me.
Next time, try “May I finish?” If that’s not enough, try these other tips from Wendy R.S. O’Connor.
3. Context
Others don't always see what's obvious to you.
Through explanation, you help others see the big picture. If a senior knows it, you help them see where your work fits.
4. Don't ask questions in statements
“Your statement lost its effect when you ended it on a high pitch,” a group member told me. Upspeak, it’s called. I do it when I feel uncertain.
Upspeak loses influence and credibility. Unneeded. When unsure, we can say "I think." We can even ask a proper question.
Someone else's boasting is no reason to be dismissive. As leaders and colleagues, we should listen to our colleagues even if they use this speech pattern.
Give your words impact.
5. Signpost structure
Signposts improve clarity by providing structure and transitions.
Communication coach Alexander Lyon explains how to use "first," "second," and "third" He explains classic and summary transitions to help the listener switch topics.
Signs clarify. Clarity matters.

6. Eliminate email fluff
“Fine. When will the report be ready? — Jeff.”
Notice how senior leaders write short, direct emails? I often use formalities like "dear," "hope you're well," and "kind regards"
Formality is (usually) unnecessary.
7. Replace exclamation marks with periods
See how junior an exclamation-filled email looks:
Hi, all!
Hope you’re as excited as I am for tomorrow! We’re celebrating our accomplishments with cake! Join us tomorrow at 2 pm!
See you soon!
Why the exclamation points? Why not just one?
Hi, all.
Hope you’re as excited as I am for tomorrow. We’re celebrating our accomplishments with cake. Join us tomorrow at 2 pm!
See you soon.
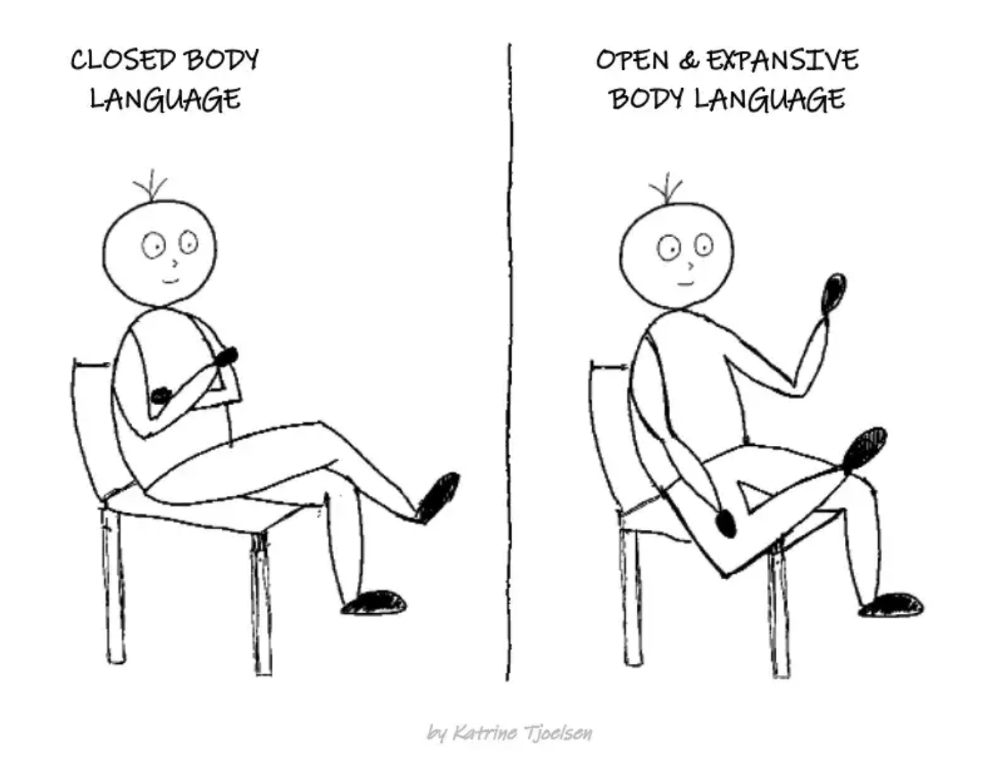
8. Take space
"Playing high" means having an open, relaxed body, says Stanford professor and author Deborah Gruenfield.
Crossed legs or looking small? Relax. Get bigger.

Yusuf Ibrahim
4 years ago
How to sell 10,000 NFTs on OpenSea for FREE (Puppeteer/NodeJS)
So you've finished your NFT collection and are ready to sell it. Except you can't figure out how to mint them! Not sure about smart contracts or want to avoid rising gas prices. You've tried and failed with apps like Mini mouse macro, and you're not familiar with Selenium/Python. Worry no more, NodeJS and Puppeteer have arrived!
Learn how to automatically post and sell all 1000 of my AI-generated word NFTs (Nakahana) on OpenSea for FREE!
My NFT project — Nakahana |
NOTE: Only NFTs on the Polygon blockchain can be sold for free; Ethereum requires an initiation charge. NFTs can still be bought with (wrapped) ETH.
If you want to go right into the code, here's the GitHub link: https://github.com/Yusu-f/nftuploader
Let's start with the knowledge and tools you'll need.
What you should know
You must be able to write and run simple NodeJS programs. You must also know how to utilize a Metamask wallet.
Tools needed
- NodeJS. You'll need NodeJs to run the script and NPM to install the dependencies.
- Puppeteer – Use Puppeteer to automate your browser and go to sleep while your computer works.
- Metamask – Create a crypto wallet and sign transactions using Metamask (free). You may learn how to utilize Metamask here.
- Chrome – Puppeteer supports Chrome.
Let's get started now!
Starting Out
Clone Github Repo to your local machine. Make sure that NodeJS, Chrome, and Metamask are all installed and working. Navigate to the project folder and execute npm install. This installs all requirements.
Replace the “extension path” variable with the Metamask chrome extension path. Read this tutorial to find the path.
Substitute an array containing your NFT names and metadata for the “arr” variable and the “collection_name” variable with your collection’s name.
Run the script.
After that, run node nftuploader.js.
Open a new chrome instance (not chromium) and Metamask in it. Import your Opensea wallet using your Secret Recovery Phrase or create a new one and link it. The script will be unable to continue after this but don’t worry, it’s all part of the plan.
Next steps
Open your terminal again and copy the route that starts with “ws”, e.g. “ws:/localhost:53634/devtools/browser/c07cb303-c84d-430d-af06-dd599cf2a94f”. Replace the path in the connect function of the nftuploader.js script.
const browser = await puppeteer.connect({ browserWSEndpoint: "ws://localhost:58533/devtools/browser/d09307b4-7a75-40f6-8dff-07a71bfff9b3", defaultViewport: null });
Rerun node nftuploader.js. A second tab should open in THE SAME chrome instance, navigating to your Opensea collection. Your NFTs should now start uploading one after the other! If any errors occur, the NFTs and errors are logged in an errors.log file.
Error Handling
The errors.log file should show the name of the NFTs and the error type. The script has been changed to allow you to simply check if an NFT has already been posted. Simply set the “searchBeforeUpload” setting to true.
We're done!
If you liked it, you can buy one of my NFTs! If you have any concerns or would need a feature added, please let me know.
Thank you to everyone who has read and liked. I never expected it to be so popular.

Scott Hickmann
4 years ago
Welcome
Welcome to Integrity's Web3 community!