




More on Technology

Sukhad Anand
3 years ago
How Do Discord's Trillions Of Messages Get Indexed?
They depend heavily on open source..

Discord users send billions of messages daily. Users wish to search these messages. How do we index these to search by message keywords?
Let’s find out.
Discord utilizes Elasticsearch. Elasticsearch is a free, open search engine for textual, numerical, geographical, structured, and unstructured data. Apache Lucene powers Elasticsearch.
How does elastic search store data? It stores it as numerous key-value pairs in JSON documents.
How does elastic search index? Elastic search's index is inverted. An inverted index lists every unique word in every page and where it appears.
4. Elasticsearch indexes documents and generates an inverted index to make data searchable in near real-time. The index API adds or updates JSON documents in a given index.
Let's examine how discord uses Elastic Search. Elasticsearch prefers bulk indexing. Discord couldn't index real-time messages. You can't search posted messages. You want outdated messages.
6. Let's check what bulk indexing requires.
1. A temporary queue for incoming communications.
2. Indexer workers that index messages into elastic search.
Discord's queue is Celery. The queue is open-source. Elastic search won't run on a single server. It's clustered. Where should a message go? Where?
8. A shard allocator decides where to put the message. Nevertheless. Shattered? A shard combines elastic search and index on. So, these two form a shard which is used as a unit by discord. The elastic search itself has some shards. But this is different, so don’t get confused.
Now, the final part is service discovery — to discover the elastic search clusters and the hosts within that cluster. This, they do with the help of etcd another open source tool.
A great thing to notice here is that discord relies heavily on open source systems and their base implementations which is very different from a lot of other products.

Gajus Kuizinas
3 years ago
How a few lines of code were able to eliminate a few million queries from the database
I was entering tens of millions of records per hour when I first published Slonik PostgreSQL client for Node.js. The data being entered was usually flat, making it straightforward to use INSERT INTO ... SELECT * FROM unnset() pattern. I advocated the unnest approach for inserting rows in groups (that was part I).

However, today I’ve found a better way: jsonb_to_recordset.
jsonb_to_recordsetexpands the top-level JSON array of objects to a set of rows having the composite type defined by an AS clause.
jsonb_to_recordset allows us to query and insert records from arbitrary JSON, like unnest. Since we're giving JSON to PostgreSQL instead of unnest, the final format is more expressive and powerful.
SELECT *
FROM json_to_recordset('[{"name":"John","tags":["foo","bar"]},{"name":"Jane","tags":["baz"]}]')
AS t1(name text, tags text[]);
name | tags
------+-----------
John | {foo,bar}
Jane | {baz}
(2 rows)Let’s demonstrate how you would use it to insert data.
Inserting data using json_to_recordset
Say you need to insert a list of people with attributes into the database.
const persons = [
{
name: 'John',
tags: ['foo', 'bar']
},
{
name: 'Jane',
tags: ['baz']
}
];You may be tempted to traverse through the array and insert each record separately, e.g.
for (const person of persons) {
await pool.query(sql`
INSERT INTO person (name, tags)
VALUES (
${person.name},
${sql.array(person.tags, 'text[]')}
)
`);
}It's easier to read and grasp when working with a few records. If you're like me and troubleshoot a 2M+ insert query per day, batching inserts may be beneficial.

What prompted the search for better alternatives.
Inserting using unnest pattern might look like this:
await pool.query(sql`
INSERT INTO public.person (name, tags)
SELECT t1.name, t1.tags::text[]
FROM unnest(
${sql.array(['John', 'Jane'], 'text')},
${sql.array(['{foo,bar}', '{baz}'], 'text')}
) AS t1.(name, tags);
`);You must convert arrays into PostgreSQL array strings and provide them as text arguments, which is unsightly. Iterating the array to create slices for each column is likewise unattractive.
However, with jsonb_to_recordset, we can:
await pool.query(sql`
INSERT INTO person (name, tags)
SELECT *
FROM jsonb_to_recordset(${sql.jsonb(persons)}) AS t(name text, tags text[])
`);In contrast to the unnest approach, using jsonb_to_recordset we can easily insert complex nested data structures, and we can pass the original JSON document to the query without needing to manipulate it.
In terms of performance they are also exactly the same. As such, my current recommendation is to prefer jsonb_to_recordset whenever inserting lots of rows or nested data structures.
Thomas Smith
3 years ago
ChatGPT Is Experiencing a Lightbulb Moment
Why breakthrough technologies must be accessible

ChatGPT has exploded. Over 1 million people have used the app, and coding sites like Stack Overflow have banned its answers. It's huge.
I wouldn't have called that as an AI researcher. ChatGPT uses the same GPT-3 technology that's been around for over two years.
More than impressive technology, ChatGPT 3 shows how access makes breakthroughs usable. OpenAI has finally made people realize the power of AI by packaging GPT-3 for normal users.
We think of Thomas Edison as the inventor of the lightbulb, not because he invented it, but because he popularized it.
Going forward, AI companies that make using AI easy will thrive.
Use-case importance
Most modern AI systems use massive language models. These language models are trained on 6,000+ years of human text.
GPT-3 ate 8 billion pages, almost every book, and Wikipedia. It created an AI that can write sea shanties and solve coding problems.
Nothing new. I began beta testing GPT-3 in 2020, but the system's basics date back further.
Tools like GPT-3 are hidden in many apps. Many of the AI writing assistants on this platform are just wrappers around GPT-3.
Lots of online utilitarian text, like restaurant menu summaries or city guides, is written by AI systems like GPT-3. You've probably read GPT-3 without knowing it.
Accessibility
Why is ChatGPT so popular if the technology is old?
ChatGPT makes the technology accessible. Free to use, people can sign up and text with the chatbot daily. ChatGPT isn't revolutionary. It does it in a way normal people can access and be amazed by.
Accessibility isn't easy. OpenAI's Sam Altman tweeted that opening ChatGPT to the public increased computing costs.
Each chat costs "low-digit cents" to process. OpenAI probably spends several hundred thousand dollars a day to keep ChatGPT running, with no immediate business case.
Academic researchers and others who developed GPT-3 couldn't afford it. Without resources to make technology accessible, it can't be used.
Retrospective
This dynamic is old. In the history of science, a researcher with a breakthrough idea was often overshadowed by an entrepreneur or visionary who made it accessible to the public.
We think of Thomas Edison as the inventor of the lightbulb. But really, Vasilij Petrov, Thomas Wright, and Joseph Swan invented the lightbulb. Edison made technology visible and accessible by electrifying public buildings, building power plants, and wiring.
Edison probably lost a ton of money on stunts like building a power plant to light JP Morgan's home, the NYSE, and several newspaper headquarters.
People wanted electric lights once they saw their benefits. By making the technology accessible and visible, Edison unlocked a hugely profitable market.
Similar things are happening in AI. ChatGPT shows that developing breakthrough technology in the lab or on B2B servers won't change the culture.
AI must engage people's imaginations to become mainstream. Before the tech impacts the world, people must play with it and see its revolutionary power.
As the field evolves, companies that make the technology widely available, even at great cost, will succeed.
OpenAI's compute fees are eye-watering. Revolutions are costly.
You might also like

Isaiah McCall
3 years ago
There is a new global currency emerging, but it is not bitcoin.
America should avoid BRICS

Vladimir Putin has watched videos of Muammar Gaddafi's CIA-backed demise.
Gaddafi...
Thief.
Did you know Gaddafi wanted a gold-backed dinar for Africa? Because he considered our global financial system was a Ponzi scheme, he wanted to discontinue trading oil in US dollars.
Or, Gaddafi's Libya enjoyed Africa's highest quality of living before becoming freed. Pictured:

Vladimir Putin is a nasty guy, but he had his reasons for not mentioning NATO assisting Ukraine in resisting US imperialism. Nobody tells you. Sure.
The US dollar's corruption post-2008, debasement by quantitative easing, and lack of value are key factors. BRICS will replace the dollar.
BRICS aren't bricks.
Economy-related.
Brazil, Russia, India, China, and South Africa have cooperated for 14 years to fight U.S. hegemony with a new international currency: BRICS.
BRICS is mostly comical. Now. Saudi Arabia, the second-largest oil hegemon, wants to join.
So what?
The New World Currency is BRICS
Russia was kicked out of G8 for its aggressiveness in Crimea in 2014.
It's now G7.
No biggie, said Putin, he said, and I quote, “Bon appetite.”
He was prepared. China, India, and Brazil lead the New World Order.
Together, they constitute 40% of the world's population and, according to the IMF, 50% of the world's GDP by 2030.
Here’s what the BRICS president Marcos Prado Troyjo had to say earlier this year about no longer needing the US dollar: “We have implemented the mechanism of mutual settlements in rubles and rupees, and there is no need for our countries to use the dollar in mutual settlements. And today a similar mechanism of mutual settlements in rubles and yuan is being developed by China.”
Ick. That's D.C. and NYC warmongers licking their chops for WW3 nasty.
Here's a lovely picture of BRICS to relax you:

If Saudi Arabia joins BRICS, as President Mohammed Bin Salman has expressed interest, a majority of the Middle East will have joined forces to construct a new world order not based on the US currency.
I'm not sure of the new acronym.
SBRICSS? CIRBSS? CRIBSS?
The Reason America Is Harvesting What It Sowed
BRICS began 14 years ago.
14 years ago, what occurred? Concentrate. It involved CDOs, bad subprime mortgages, and Wall Street quants crunching numbers.
2008 recession
When two nations trade, they do so in US dollars, not Euros or gold.
What happened when 2008, an avoidable crisis caused by US banks' cupidity and ignorance, what happened?
Everyone WORLDWIDE felt the pain.
Mostly due to corporate America's avarice.
This should have been a warning that China and Russia had enough of our bs. Like when France sent a battleship to America after Nixon scrapped the gold standard. The US was warned to shape up or be dethroned (or at least try).

Nixon improved in 1971. Kinda. Invented PetroDollar.
Another BS system that unfairly favors America and possibly pushed Russia, China, and Saudi Arabia into BRICS.
The PetroDollar forces oil-exporting nations to trade in US dollars and invest in US Treasury bonds. Brilliant. Genius evil.
Our misdeeds are:
In conflicts that are not its concern, the USA uses the global reserve currency as a weapon.
Targeted nations abandon the dollar, and rightfully so, as do nations that depend on them for trade in vital resources.
The dollar's position as the world's reserve currency is in jeopardy, which could have disastrous economic effects.
Although we have actually sown our own doom, we appear astonished. According to the Bible, whomever sows to appease his sinful nature will reap destruction from that nature whereas whoever sows to appease the Spirit will reap eternal life from the Spirit.
Americans, even our leaders, lack caution and delayed pleasure. When our unsustainable systems fail, we double down. Bailouts of the banks in 2008 were myopic, puerile, and another nail in America's hegemony.
America has screwed everyone.
We're unpopular.
The BRICS's future
It's happened before.
Saddam Hussein sold oil in Euros in 2000, and the US invaded Iraq a month later. The media has devalued the word conspiracy. The Iraq conspiracy.
There were no WMDs, but NYT journalists like Judy Miller drove Americans into a warmongering frenzy because Saddam would ruin the PetroDollar. Does anyone recall that this war spawned ISIS?
I think America has done good for the world. You can make a convincing case that we're many people's villain.
Learn more in Confessions of an Economic Hitman, The Devil's Chessboard, or Tyranny of the Federal Reserve. Or ignore it. That's easier.
We, America, should extend an olive branch, ask for forgiveness, and learn from our faults, as the Tao Te Ching advises. Unlikely. Our population is apathetic and stupid, and our government is corrupt.
Argentina, Iran, Egypt, and Turkey have also indicated interest in joining BRICS. They're also considering making it gold-backed, making it a new world reserve currency.
You should pay attention.
Thanks for reading!

Laura Sanders
3 years ago
Xenobots, tiny living machines, can duplicate themselves.
Strange and complex behavior of frog cell blobs
A xenobot “parent,” shaped like a hungry Pac-Man (shown in red false color), created an “offspring” xenobot (green sphere) by gathering loose frog cells in its opening.
Tiny “living machines” made of frog cells can make copies of themselves. This newly discovered renewal mechanism may help create self-renewing biological machines.
According to Kirstin Petersen, an electrical and computer engineer at Cornell University who studies groups of robots, “this is an extremely exciting breakthrough.” She says self-replicating robots are a big step toward human-free systems.
Researchers described the behavior of xenobots earlier this year (SN: 3/31/21). Small clumps of skin stem cells from frog embryos knitted themselves into small spheres and started moving. Cilia, or cellular extensions, powered the xenobots around their lab dishes.
The findings are published in the Proceedings of the National Academy of Sciences on Dec. 7. The xenobots can gather loose frog cells into spheres, which then form xenobots.
The researchers call this type of movement-induced reproduction kinematic self-replication. The study's coauthor, Douglas Blackiston of Tufts University in Medford, Massachusetts, and Harvard University, says this is typical. For example, sexual reproduction requires parental sperm and egg cells. Sometimes cells split or budded off from a parent.
“This is unique,” Blackiston says. These xenobots “find loose parts in the environment and cobble them together.” This second generation of xenobots can move like their parents, Blackiston says.
The researchers discovered that spheroid xenobots could only produce one more generation before dying out. The original xenobots' shape was predicted by an artificial intelligence program, allowing for four generations of replication.
A C shape, like an openmouthed Pac-Man, was predicted to be a more efficient progenitor. When improved xenobots were let loose in a dish, they began scooping up loose cells into their gaping “mouths,” forming more sphere-shaped bots (see image below). As many as 50 cells clumped together in the opening of a parent to form a mobile offspring. A xenobot is made up of 4,000–6,000 frog cells.
Petersen likes the Xenobots' small size. “The fact that they were able to do this at such a small scale just makes it even better,” she says. Miniature xenobots could sculpt tissues for implantation or deliver therapeutics inside the body.
Beyond the xenobots' potential jobs, the research advances an important science, says study coauthor and Tufts developmental biologist Michael Levin. The science of anticipating and controlling the outcomes of complex systems, he says.
“No one could have predicted this,” Levin says. “They regularly surprise us.” Researchers can use xenobots to test the unexpected. “This is about advancing the science of being less surprised,” Levin says.

Grace Huang
3 years ago
I sold 100 copies of my book when I had anticipated selling none.
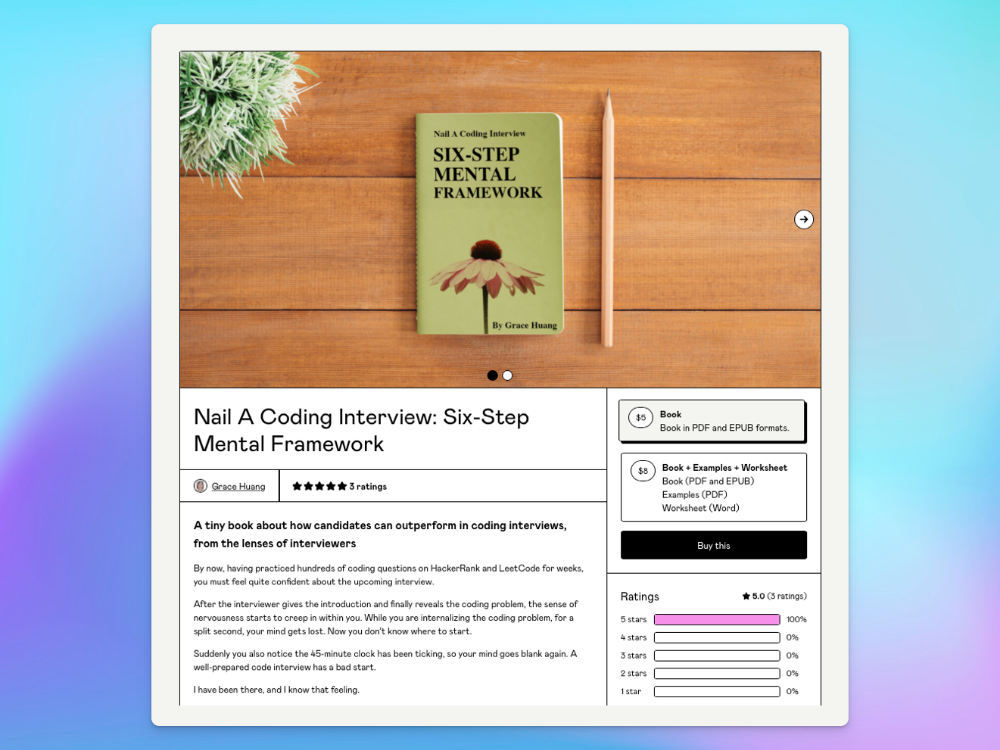
After a decade in large tech, I know how software engineers were interviewed. I've seen outstanding engineers fail interviews because their responses were too vague.
So I wrote Nail A Coding Interview: Six-Step Mental Framework. Give candidates a mental framework for coding questions; help organizations better prepare candidates so they can calibrate traits.
Recently, I sold more than 100 books, something I never expected.
In this essay, I'll describe my publication journey, which included self-doubt and little triumphs. I hope this helps if you want to publish.
It was originally a Medium post.
How did I know to develop a coding interview book? Years ago, I posted on Medium.
Six steps to ace a coding interview Inhale. blog.devgenius.io
This story got a lot of attention and still gets a lot of daily traffic. It indicates this domain's value.
Converted the Medium article into an ebook
The Medium post contains strong bullet points, but it is missing the “flesh”. How to use these strategies in coding interviews, for example. I filled in the blanks and made a book.
I made the book cover for free. It's tidy.
Shared the article with my close friends on my social network WeChat.
I shared the book on Wechat's Friend Circle (朋友圈) after publishing it on Gumroad. Many friends enjoyed my post. It definitely triggered endorphins.
In Friend Circle, I presented a 100% off voucher. No one downloaded the book. Endorphins made my heart sink.
Several days later, my Apple Watch received a Gumroad notification. A friend downloaded it. I majored in finance, he subsequently said. My brother-in-law can get it? He downloaded it to cheer me up.
I liked him, but was disappointed that he didn't read it.
The Tipping Point: Reddit's Free Giving
I trusted the book. It's based on years of interviewing. I felt it might help job-hunting college students. If nobody wants it, it can still have value.
I posted the book's link on /r/leetcode. I told them to DM me for a free promo code.
Momentum shifted everything. Gumroad notifications kept coming when I was out with family. Following orders.
As promised, I sent DMs a promo code. Some consumers ordered without asking for a promo code. Some readers finished the book and posted reviews.
My book was finally on track.
A 5-Star Review, plus More
A reader afterwards DMed me and inquired if I had another book on system design interviewing. I said that was a good idea, but I didn't have one. If you write one, I'll be your first reader.
Later, I asked for a book review. Yes, but how? That's when I learned readers' reviews weren't easy. I built up an email pipeline to solicit customer reviews. Since then, I've gained credibility through ratings.
Learnings
I wouldn't have gotten 100 if I gave up when none of my pals downloaded. Here are some lessons.
Your friends are your allies, but they are not your clients.
Be present where your clients are
Request ratings and testimonials
gain credibility gradually
I did it, so can you. Follow me on Twitter @imgracehuang for my publishing and entrepreneurship adventure.