



More on Technology

Al Anany
3 years ago
Notion AI Might Destroy Grammarly and Jasper
The trick Notion could use is simply Facebook-ing the hell out of them.

*Time travel to fifteen years ago.* Future-Me: “Hey! What are you up to?” Old-Me: “I am proofreading an article. It’s taking a few hours, but I will be done soon.” Future-Me: “You know, in the future, you will be using a google chrome plugin called Grammarly that will help you easily proofread articles in half that time.” Old-Me: “What is… Google Chrome?” Future-Me: “Gosh…”
I love Grammarly. It’s one of those products that I personally feel the effects of. I mean, Space X is a great company. But I am not a rocket writing this article in space (or am I?)…
No, I’m not. So I don’t personally feel a connection to Space X. So, if a company collapse occurs in the morning, I might write about it. But I will have zero emotions regarding it.
Yet, if Grammarly fails tomorrow, I will feel 1% emotionally distressed. So looking at the title of this article, you’d realize that I am betting against them. This is how much I believe in the critical business model that’s taking over the world, the one of Notion.
Notion How frequently do you go through your notes?
Grammarly is everywhere, which helps its success. Grammarly is available when you update LinkedIn on Chrome. Grammarly prevents errors in Google Docs.
My internal concentration isn't apparent in the previous paragraph. Not Grammarly. I should have used Chrome to make a Google doc and LinkedIn update. Without this base, Grammarly will be useless.
So, welcome to this business essay.
Grammarly provides a solution.
Another issue is resolved by Jasper.
Your entire existence is supposed to be contained within Notion.
New Google Chrome is offline. It's an all-purpose notepad (in the near future.)
How should I start my blog? Enter it in Note.
an update on LinkedIn? If you mention it, it might be automatically uploaded there (with little help from another app.)
An advanced thesis? You can brainstorm it with your coworkers.
This ad sounds great! I won't cry if Notion dies tomorrow.
I'll reread the following passages to illustrate why I think Notion could kill Grammarly and Jasper.
Notion is a fantastic app that incubates your work.
Smartly, they began with note-taking.
Hopefully, your work will be on Notion. Grammarly and Jasper are still must-haves.
Grammarly will proofread your typing while Jasper helps with copywriting and AI picture development.
They're the best, therefore you'll need them. Correct? Nah.
Notion might bombard them with Facebook posts.
Notion: “Hi Grammarly, do you want to sell your product to us?” Grammarly: “Dude, we are more valuable than you are. We’ve even raised $400m, while you raised $342m. Our last valuation round put us at $13 billion, while yours put you at $10 billion. Go to hell.” Notion: “Okay, we’ll speak again in five years.”
Notion: “Jasper, wanna sell?” Jasper: “Nah, we’re deep into AI and the field. You can’t compete with our people.” Notion: “How about you either sell or you turn into a Snapchat case?” Jasper: “…”
Notion is your home. Grammarly is your neighbor. Your track is Jasper.
What if you grew enough vegetables in your backyard to avoid the supermarket? No more visits.
What if your home had a beautiful treadmill? You won't rush outside as much (I disagree with my own metaphor). (You get it.)
It's Facebooking. Instagram Stories reduced your Snapchat usage. Notion will reduce your need to use Grammarly.
The Final Piece of the AI Puzzle
Let's talk about Notion first, since you've probably read about it everywhere.
They raised $343 million, as I previously reported, and bought four businesses
According to Forbes, Notion will have more than 20 million users by 2022. The number of users is up from 4 million in 2020.
If raising $1.8 billion was impressive, FTX wouldn't have fallen.
This article compares the basic product to two others. Notion is a day-long app.
Notion has released Notion AI to support writers. It's early, so it's not as good as Jasper. Then-Jasper isn't now-Jasper. In five years, Notion AI will be different.
With hard work, they may construct a Jasper-like writing assistant. They have resources and users.
At this point, it's all speculation. Jasper's copywriting is top-notch. Grammarly's proofreading is top-notch. Businesses are constrained by user activities.
If Notion's future business movements are strategic, they might become a blue ocean shark (or get acquired by an unbelievable amount.)
I love business mental teasers, so tell me:
How do you feel? Are you a frequent Notion user?
Do you dispute my position? I enjoy hearing opposing viewpoints.
Ironically, I proofread this with Grammarly.

Dmitrii Eliuseev
2 years ago
Creating Images on Your Local PC Using Stable Diffusion AI
Deep learning-based generative art is being researched. As usual, self-learning is better. Some models, like OpenAI's DALL-E 2, require registration and can only be used online, but others can be used locally, which is usually more enjoyable for curious users. I'll demonstrate the Stable Diffusion model's operation on a standard PC.

Let’s get started.
What It Does
Stable Diffusion uses numerous components:
A generative model trained to produce images is called a diffusion model. The model is incrementally improving the starting data, which is only random noise. The model has an image, and while it is being trained, the reversed process is being used to add noise to the image. Being able to reverse this procedure and create images from noise is where the true magic is (more details and samples can be found in the paper).
An internal compressed representation of a latent diffusion model, which may be altered to produce the desired images, is used (more details can be found in the paper). The capacity to fine-tune the generation process is essential because producing pictures at random is not very attractive (as we can see, for instance, in Generative Adversarial Networks).
A neural network model called CLIP (Contrastive Language-Image Pre-training) is used to translate natural language prompts into vector representations. This model, which was trained on 400,000,000 image-text pairs, enables the transformation of a text prompt into a latent space for the diffusion model in the scenario of stable diffusion (more details in that paper).
This figure shows all data flow:
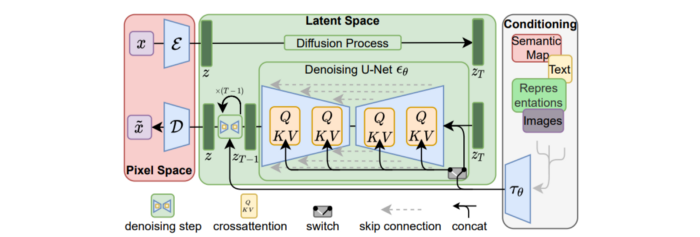
The weights file size for Stable Diffusion model v1 is 4 GB and v2 is 5 GB, making the model quite huge. The v1 model was trained on 256x256 and 512x512 LAION-5B pictures on a 4,000 GPU cluster using over 150.000 NVIDIA A100 GPU hours. The open-source pre-trained model is helpful for us. And we will.
Install
Before utilizing the Python sources for Stable Diffusion v1 on GitHub, we must install Miniconda (assuming Git and Python are already installed):
wget https://repo.anaconda.com/miniconda/Miniconda3-py39_4.12.0-Linux-x86_64.sh
chmod +x Miniconda3-py39_4.12.0-Linux-x86_64.sh
./Miniconda3-py39_4.12.0-Linux-x86_64.sh
conda update -n base -c defaults condaInstall the source and prepare the environment:
git clone https://github.com/CompVis/stable-diffusion
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm
pip3 install transformers --upgradeDownload the pre-trained model weights next. HiggingFace has the newest checkpoint sd-v14.ckpt (a download is free but registration is required). Put the file in the project folder and have fun:
python3 scripts/txt2img.py --prompt "hello world" --plms --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1Almost. The installation is complete for happy users of current GPUs with 12 GB or more VRAM. RuntimeError: CUDA out of memory will occur otherwise. Two solutions exist.
Running the optimized version
Try optimizing first. After cloning the repository and enabling the environment (as previously), we can run the command:
python3 optimizedSD/optimized_txt2img.py --prompt "hello world" --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1Stable Diffusion worked on my visual card with 8 GB RAM (alas, I did not behave well enough to get NVIDIA A100 for Christmas, so 8 GB GPU is the maximum I have;).
Running Stable Diffusion without GPU
If the GPU does not have enough RAM or is not CUDA-compatible, running the code on a CPU will be 20x slower but better than nothing. This unauthorized CPU-only branch from GitHub is easiest to obtain. We may easily edit the source code to use the latest version. It's strange that a pull request for that was made six months ago and still hasn't been approved, as the changes are simple. Readers can finish in 5 minutes:
Replace if attr.device!= torch.device(cuda) with if attr.device!= torch.device(cuda) and torch.cuda.is available at line 20 of ldm/models/diffusion/ddim.py ().
Replace if attr.device!= torch.device(cuda) with if attr.device!= torch.device(cuda) and torch.cuda.is available in line 20 of ldm/models/diffusion/plms.py ().
Replace device=cuda in lines 38, 55, 83, and 142 of ldm/modules/encoders/modules.py with device=cuda if torch.cuda.is available(), otherwise cpu.
Replace model.cuda() in scripts/txt2img.py line 28 and scripts/img2img.py line 43 with if torch.cuda.is available(): model.cuda ().
Run the script again.
Testing
Test the model. Text-to-image is the first choice. Test the command line example again:
python3 scripts/txt2img.py --prompt "hello world" --plms --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1The slow generation takes 10 seconds on a GPU and 10 minutes on a CPU. Final image:

Hello world is dull and abstract. Try a brush-wielding hamster. Why? Because we can, and it's not as insane as Napoleon's cat. Another image:

Generating an image from a text prompt and another image is interesting. I made this picture in two minutes using the image editor (sorry, drawing wasn't my strong suit):
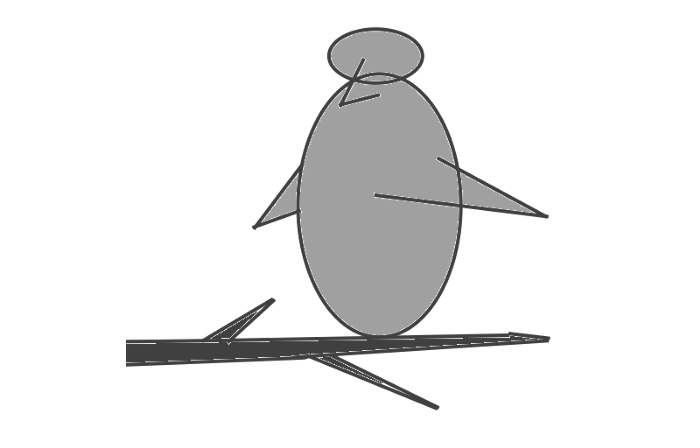
I can create an image from this drawing:
python3 scripts/img2img.py --prompt "A bird is sitting on a tree branch" --ckpt sd-v1-4.ckpt --init-img bird.png --strength 0.8It was far better than my initial drawing:

I hope readers understand and experiment.
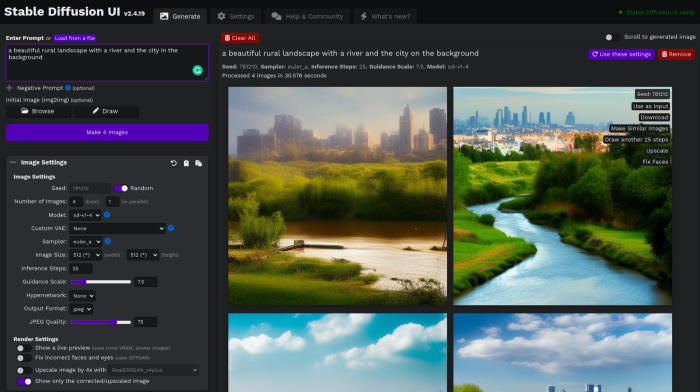
Stable Diffusion UI
Developers love the command line, but regular users may struggle. Stable Diffusion UI projects simplify image generation and installation. Simple usage:
Unpack the ZIP after downloading it from https://github.com/cmdr2/stable-diffusion-ui/releases. Linux and Windows are compatible with Stable Diffusion UI (sorry for Mac users, but those machines are not well-suitable for heavy machine learning tasks anyway;).
Start the script.
Done. The web browser UI makes configuring various Stable Diffusion features (upscaling, filtering, etc.) easy:
V2.1 of Stable Diffusion
I noticed the notification about releasing version 2.1 while writing this essay, and it was intriguing to test it. First, compare version 2 to version 1:
alternative text encoding. The Contrastive LanguageImage Pre-training (CLIP) deep learning model, which was trained on a significant number of text-image pairs, is used in Stable Diffusion 1. The open-source CLIP implementation used in Stable Diffusion 2 is called OpenCLIP. It is difficult to determine whether there have been any technical advancements or if legal concerns were the main focus. However, because the training datasets for the two text encoders were different, the output results from V1 and V2 will differ for the identical text prompts.
a new depth model that may be used to the output of image-to-image generation.
a revolutionary upscaling technique that can quadruple the resolution of an image.
Generally higher resolution Stable Diffusion 2 has the ability to produce both 512x512 and 768x768 pictures.
The Hugging Face website offers a free online demo of Stable Diffusion 2.1 for code testing. The process is the same as for version 1.4. Download a fresh version and activate the environment:
conda deactivate
conda env remove -n ldm # Use this if version 1 was previously installed
git clone https://github.com/Stability-AI/stablediffusion
cd stablediffusion
conda env create -f environment.yaml
conda activate ldmHugging Face offers a new weights ckpt file.
The Out of memory error prevented me from running this version on my 8 GB GPU. Version 2.1 fails on CPUs with the slow conv2d cpu not implemented for Half error (according to this GitHub issue, the CPU support for this algorithm and data type will not be added). The model can be modified from half to full precision (float16 instead of float32), however it doesn't make sense since v1 runs up to 10 minutes on the CPU and v2.1 should be much slower. The online demo results are visible. The same hamster painting with a brush prompt yielded this result:

It looks different from v1, but it functions and has a higher resolution.
The superresolution.py script can run the 4x Stable Diffusion upscaler locally (the x4-upscaler-ema.ckpt weights file should be in the same folder):
python3 scripts/gradio/superresolution.py configs/stable-diffusion/x4-upscaling.yaml x4-upscaler-ema.ckptThis code allows the web browser UI to select the image to upscale:
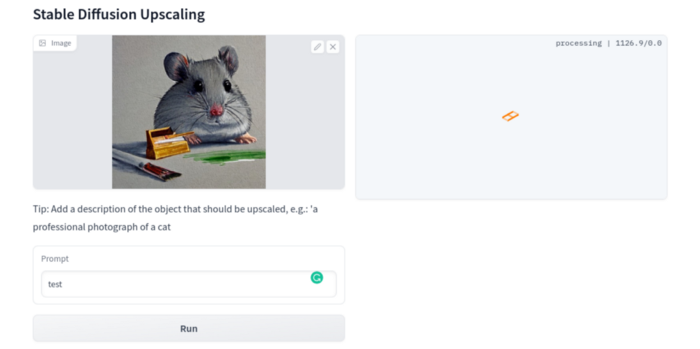
The copy-paste strategy may explain why the upscaler needs a text prompt (and the Hugging Face code snippet does not have any text input as well). I got a GPU out of memory error again, although CUDA can be disabled like v1. However, processing an image for more than two hours is unlikely:
Stable Diffusion Limitations
When we use the model, it's fun to see what it can and can't do. Generative models produce abstract visuals but not photorealistic ones. This fundamentally limits The generative neural network was trained on text and image pairs, but humans have a lot of background knowledge about the world. The neural network model knows nothing. If someone asks me to draw a Chinese text, I can draw something that looks like Chinese but is actually gibberish because I never learnt it. Generative AI does too! Humans can learn new languages, but the Stable Diffusion AI model includes only language and image decoder brain components. For instance, the Stable Diffusion model will pull NO WAR banner-bearers like this:
V1:

V2.1:

The shot shows text, although the model never learned to read or write. The model's string tokenizer automatically converts letters to lowercase before generating the image, so typing NO WAR banner or no war banner is the same.
I can also ask the model to draw a gorgeous woman:
V1:

V2.1:

The first image is gorgeous but physically incorrect. A second one is better, although it has an Uncanny valley feel. BTW, v2 has a lifehack to add a negative prompt and define what we don't want on the image. Readers might try adding horrible anatomy to the gorgeous woman request.
If we ask for a cartoon attractive woman, the results are nice, but accuracy doesn't matter:
V1:

V2.1:

Another example: I ordered a model to sketch a mouse, which looks beautiful but has too many legs, ears, and fingers:
V1:

V2.1: improved but not perfect.

V1 produces a fun cartoon flying mouse if I want something more abstract:

I tried multiple times with V2.1 but only received this:

The image is OK, but the first version is closer to the request.
Stable Diffusion struggles to draw letters, fingers, etc. However, abstract images yield interesting outcomes. A rural landscape with a modern metropolis in the background turned out well:
V1:

V2.1:

Generative models help make paintings too (at least, abstract ones). I searched Google Image Search for modern art painting to see works by real artists, and this was the first image:

I typed "abstract oil painting of people dancing" and got this:
V1:

V2.1:

It's a different style, but I don't think the AI-generated graphics are worse than the human-drawn ones.
The AI model cannot think like humans. It thinks nothing. A stable diffusion model is a billion-parameter matrix trained on millions of text-image pairs. I input "robot is creating a picture with a pen" to create an image for this post. Humans understand requests immediately. I tried Stable Diffusion multiple times and got this:

This great artwork has a pen, robot, and sketch, however it was not asked. Maybe it was because the tokenizer deleted is and a words from a statement, but I tried other requests such robot painting picture with pen without success. It's harder to prompt a model than a person.
I hope Stable Diffusion's general effects are evident. Despite its limitations, it can produce beautiful photographs in some settings. Readers who want to use Stable Diffusion results should be warned. Source code examination demonstrates that Stable Diffusion images feature a concealed watermark (text StableDiffusionV1 and SDV2) encoded using the invisible-watermark Python package. It's not a secret, because the official Stable Diffusion repository's test watermark.py file contains a decoding snippet. The put watermark line in the txt2img.py source code can be removed if desired. I didn't discover this watermark on photographs made by the online Hugging Face demo. Maybe I did something incorrectly (but maybe they are just not using the txt2img script on their backend at all).
Conclusion
The Stable Diffusion model was fascinating. As I mentioned before, trying something yourself is always better than taking someone else's word, so I encourage readers to do the same (including this article as well;).
Is Generative AI a game-changer? My humble experience tells me:
I think that place has a lot of potential. For designers and artists, generative AI can be a truly useful and innovative tool. Unfortunately, it can also pose a threat to some of them since if users can enter a text field to obtain a picture or a website logo in a matter of clicks, why would they pay more to a different party? Is it possible right now? unquestionably not yet. Images still have a very poor quality and are erroneous in minute details. And after viewing the image of the stunning woman above, models and fashion photographers may also unwind because it is highly unlikely that AI will replace them in the upcoming years.
Today, generative AI is still in its infancy. Even 768x768 images are considered to be of a high resolution when using neural networks, which are computationally highly expensive. There isn't an AI model that can generate high-resolution photographs natively without upscaling or other methods, at least not as of the time this article was written, but it will happen eventually.
It is still a challenge to accurately represent knowledge in neural networks (information like how many legs a cat has or the year Napoleon was born). Consequently, AI models struggle to create photorealistic photos, at least where little details are important (on the other side, when I searched Google for modern art paintings, the results are often even worse;).
When compared to the carefully chosen images from official web pages or YouTube reviews, the average output quality of a Stable Diffusion generation process is actually less attractive because to its high degree of randomness. When using the same technique on their own, consumers will theoretically only view those images as 1% of the results.
Anyway, it's exciting to witness this area's advancement, especially because the project is open source. Google's Imagen and DALL-E 2 can also produce remarkable findings. It will be interesting to see how they progress.

Jano le Roux
3 years ago
Apple Quietly Introduces A Revolutionary Savings Account That Kills Banks
Would you abandon your bank for Apple?

Banks are struggling.
not as a result of inflation
not due to the economic downturn.
not due to the conflict in Ukraine.
But because they’re underestimating Apple.
Slowly but surely, Apple is looking more like a bank.
An easy new savings account like Apple
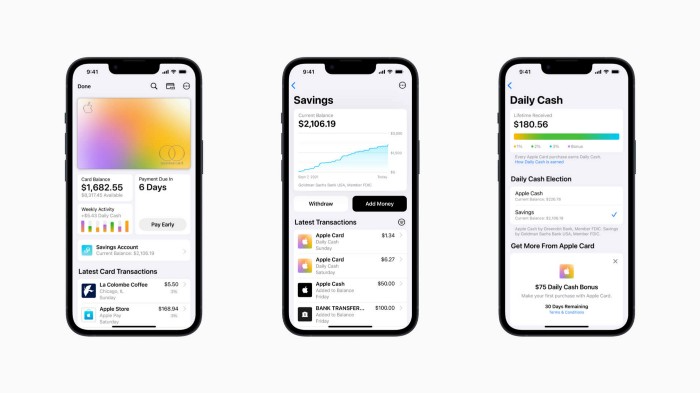
Apple has a new savings account.
Apple says Apple Card users may set up and manage savings straight in Wallet.
No more charges
Colorfully high yields
With no minimum balance
No minimal down payments
Most consumer-facing banks will have to match Apple's offer or suffer disruption.
Users may set it up from their iPhones without traveling to a bank or filling out paperwork.
It’s built into the iPhone in your pocket.
So now more waiting for slow approval processes.
Once the savings account is set up, Apple will automatically transfer all future Daily Cash into it. Users may also add these cash to an Apple Cash card in their Apple Wallet app and adjust where Daily Cash is paid at any time.
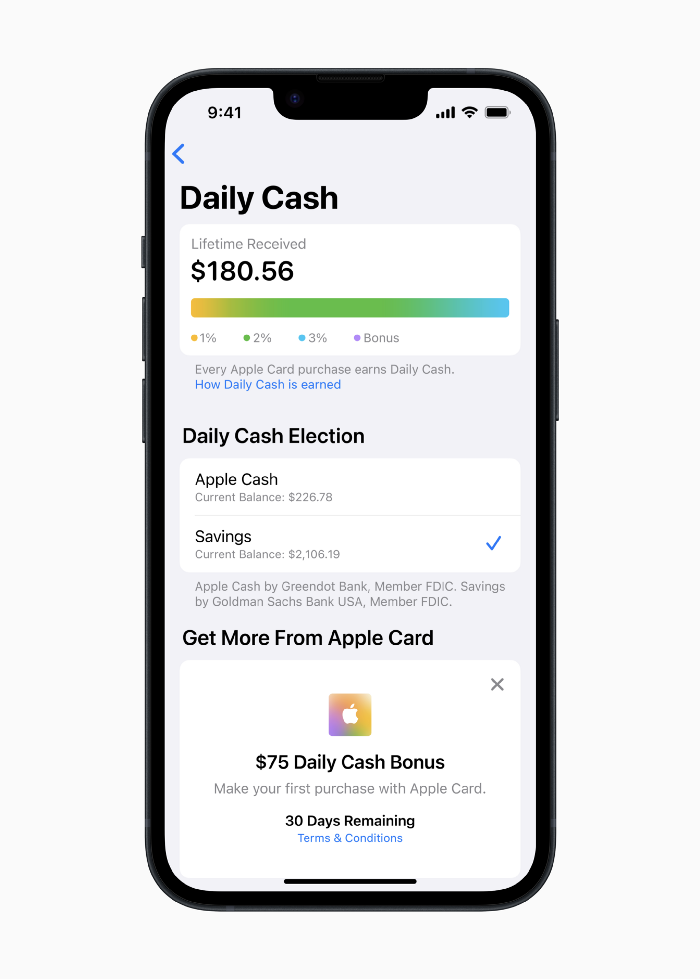
Apple Pay and Apple Wallet VP Jennifer Bailey:
Savings enables Apple Card users to grow their Daily Cash rewards over time, while also saving for the future.
Bailey says Savings adds value to Apple Card's Daily Cash benefit and offers another easy-to-use tool to help people lead healthier financial lives.
Transfer money from a linked bank account or Apple Cash to a Savings account. Users can withdraw monies to a connected bank account or Apple Cash card without costs.
Once set up, Apple Card customers can track their earnings via Wallet's Savings dashboard. This dashboard shows their account balance and interest.
This product targets younger people as the easiest way to start a savings account on the iPhone.
Why would a Gen Z account holder travel to the bank if their iPhone could be their bank?
Using this concept, Apple will transform the way we think about banking by 2030.
Two other nightmares keep bankers awake at night
Apple revealed two new features in early 2022 that banks and payment gateways hated.
Tap to Pay with Apple
Late Apple Pay
They startled the industry.
Tap To Pay converts iPhones into mobile POS card readers. Apple Pay Later is pushing the BNPL business in a consumer-friendly direction, hopefully ending dodgy lending practices.
Tap to Pay with Apple
iPhone POS

Millions of US merchants, from tiny shops to huge establishments, will be able to accept Apple Pay, contactless credit and debit cards, and other digital wallets with a tap.
No hardware or payment terminal is needed.
Revolutionary!
Stripe has previously launched this feature.
Tap to Pay on iPhone will provide companies with a secure, private, and quick option to take contactless payments and unleash new checkout experiences, said Bailey.
Apple's solution is ingenious. Brilliant!
Bailey says that payment platforms, app developers, and payment networks are making it easier than ever for businesses of all sizes to accept contactless payments and thrive.
I admire that Apple is offering this up to third-party services instead of closing off other functionalities.
Slow POS terminals, farewell.
Late Apple Pay
Pay Apple later.
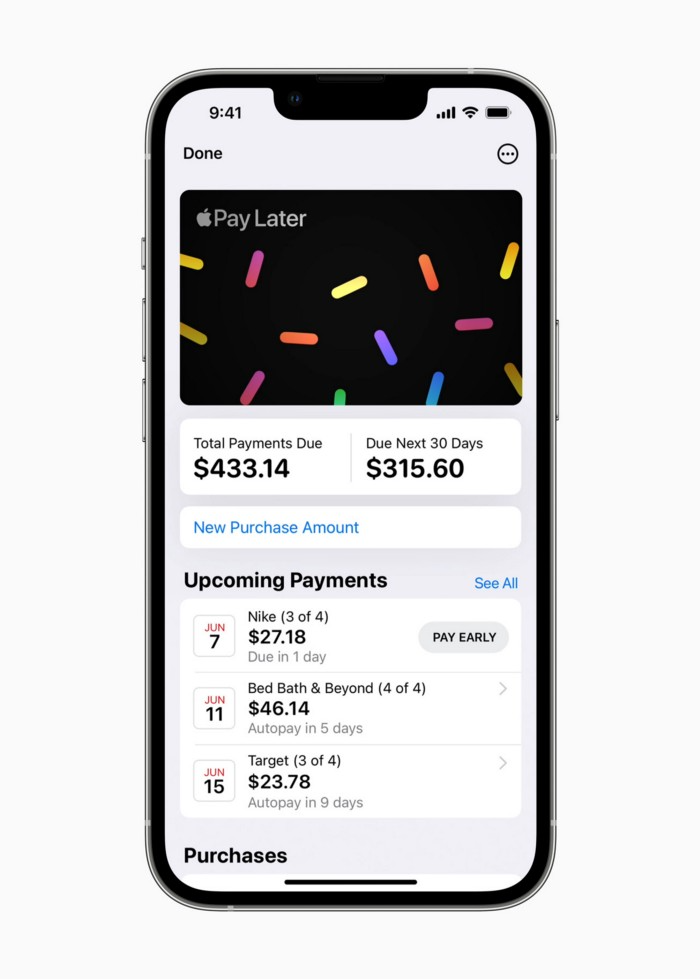
Apple Pay Later enables US consumers split Apple Pay purchases into four equal payments over six weeks with no interest or fees.
The Apple ecosystem integration makes this BNPL scheme unique. Nonstick. No dumb forms.
Frictionless.
Just double-tap the button.
Apple Pay Later was designed with users' financial well-being in mind. Apple makes it easy to use, track, and pay back Apple Pay Later from Wallet.
Apple Pay Later can be signed up in Wallet or when using Apple Pay. Apple Pay Later can be used online or in an app that takes Apple Pay and leverages the Mastercard network.
Apple Pay Order Tracking helps consumers access detailed receipts and order tracking in Wallet for Apple Pay purchases at participating stores.
Bad BNPL suppliers, goodbye.
Most bankers will be caught in Apple's eye playing mini golf in high-rise offices.
The big problem:
Banks still think about features and big numbers just like other smartphone makers did not too long ago.
Apple thinks about effortlessness, seamlessness, and frictionlessness that just work through integrated hardware and software.
Let me know what you think Apple’s next power moves in the banking industry could be.
You might also like

Eve Arnold
3 years ago
Your Ideal Position As a Part-Time Creator
Inspired by someone I never met

Inspiration is good and bad.
Paul Jarvis inspires me. He's a web person and writer who created his own category by being himself.
Paul said no thank you when everyone else was developing, building, and assuming greater responsibilities. This isn't success. He rewrote the rules. Working for himself, expanding at his own speed, and doing what he loves were his definitions of success.
Play with a problem that you have
The biggest problem can be not recognizing a problem.
Acceptance without question is deception. When you don't push limits, you forget how. You start thinking everything must be as it is.
For example: working. Paul worked a 9-5 agency work with little autonomy. He questioned whether the 9-5 was a way to live, not the way.
Another option existed. So he chipped away at how to live in this new environment.
Don't simply jump
Internet writers tell people considering quitting 9-5 to just quit. To throw in the towel. To do what you like.
The advice is harmful, despite the good intentions. People think quitting is hard. Like courage is the issue. Like handing your boss a resignation letter.
Nope. The tough part comes after. It’s easy to jump. Landing is difficult.
The landing
Paul didn't quit. Intelligent individuals don't. Smart folks focus on landing. They imagine life after 9-5.
Paul had been a web developer for a long time, had solid clients, and was respected. Hence if he pushed the limits and discovered another route, he had the potential to execute.
Working on the side
Society loves polarization. It’s left or right. Either way. Or chaos. It's 9-5 or entrepreneurship.
But like Paul, you can stretch polarization's limits. In-between exists.
You can work a 9-5 and side jobs (as I do). A mix of your favorites. The 9-5's stability and creativity. Fire and routine.
Remember you can't have everything but anything. You can create and work part-time.
My hybrid lifestyle
Not selling books doesn't destroy my world. My globe keeps spinning if my new business fails or if people don't like my Tweets. Unhappy algorithm? Cool. I'm not bothered (okay maybe a little).
The mix gives me the best of both worlds. To create, hone my skill, and grasp big-business basics. I like routine, but I also appreciate spending 4 hours on Saturdays writing.
Some days I adore leaving work at 5 pm and disconnecting. Other days, I adore having a place to write if inspiration strikes during a run or a discussion.
I’m a part-time creator
I’m a part-time creator. No, I'm not trying to quit. I don't work 5 pm - 2 am on the side. No, I'm not at $10,000 MRR.
I work part-time but enjoy my 9-5. My 9-5 has goodies. My side job as well.
It combines both to meet my lifestyle. I'm satisfied.
Join the Part-time Creators Club for free here. I’ll send you tips to enhance your creative game.

Farhan Ali Khan
2 years ago
Introduction to Zero-Knowledge Proofs: The Art of Proving Without Revealing
Zero-Knowledge Proofs for Beginners
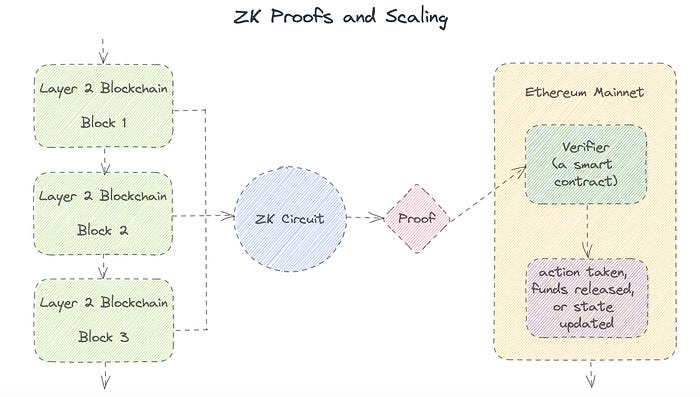
Published here originally.
Introduction
I Spy—did you play as a kid? One person chose a room object, and the other had to guess it by answering yes or no questions. I Spy was entertaining, but did you know it could teach you cryptography?
Zero Knowledge Proofs let you show your pal you know what they picked without exposing how. Math replaces electronics in this secret spy mission. Zero-knowledge proofs (ZKPs) are sophisticated cryptographic tools that allow one party to prove they have particular knowledge without revealing it. This proves identification and ownership, secures financial transactions, and more. This article explains zero-knowledge proofs and provides examples to help you comprehend this powerful technology.
What is a Proof of Zero Knowledge?
Zero-knowledge proofs prove a proposition is true without revealing any other information. This lets the prover show the verifier that they know a fact without revealing it. So, a zero-knowledge proof is like a magician's trick: the prover proves they know something without revealing how or what. Complex mathematical procedures create a proof the verifier can verify.
Want to find an easy way to test it out? Try out with tis awesome example! ZK Crush
Describe it as if I'm 5
Alex and Jack found a cave with a center entrance that only opens when someone knows the secret. Alex knows how to open the cave door and wants to show Jack without telling him.
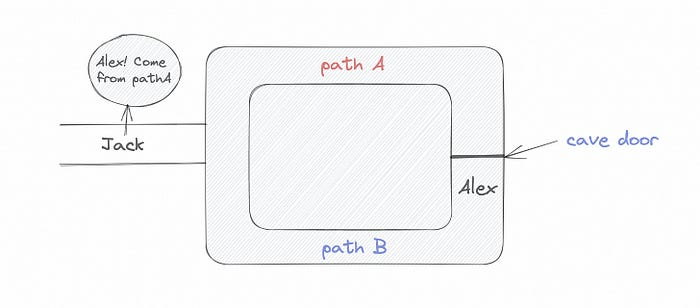
Alex and Jack name both pathways (let’s call them paths A and B).
In the first phase, Alex is already inside the cave and is free to select either path, in this case A or B.
As Alex made his decision, Jack entered the cave and asked him to exit from the B path.
Jack can confirm that Alex really does know the key to open the door because he came out for the B path and used it.
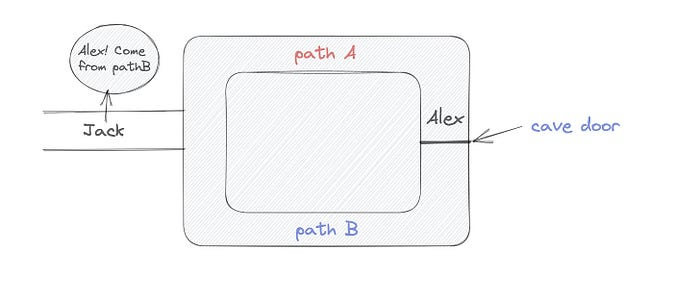
To conclude, Alex and Jack repeat:
Alex walks into the cave.
Alex follows a random route.
Jack walks into the cave.
Alex is asked to follow a random route by Jack.
Alex follows Jack's advice and heads back that way.
What is a Zero Knowledge Proof?
At a high level, the aim is to construct a secure and confidential conversation between the prover and the verifier, where the prover convinces the verifier that they have the requisite information without disclosing it. The prover and verifier exchange messages and calculate in each round of the dialogue.
The prover uses their knowledge to prove they have the information the verifier wants during these rounds. The verifier can verify the prover's truthfulness without learning more by checking the proof's mathematical statement or computation.
Zero knowledge proofs use advanced mathematical procedures and cryptography methods to secure communication. These methods ensure the evidence is authentic while preventing the prover from creating a phony proof or the verifier from extracting unnecessary information.
ZK proofs require examples to grasp. Before the examples, there are some preconditions.
Criteria for Proofs of Zero Knowledge
Completeness: If the proposition being proved is true, then an honest prover will persuade an honest verifier that it is true.
Soundness: If the proposition being proved is untrue, no dishonest prover can persuade a sincere verifier that it is true.
Zero-knowledge: The verifier only realizes that the proposition being proved is true. In other words, the proof only establishes the veracity of the proposition being supported and nothing more.
The zero-knowledge condition is crucial. Zero-knowledge proofs show only the secret's veracity. The verifier shouldn't know the secret's value or other details.
Example after example after example
To illustrate, take a zero-knowledge proof with several examples:
Initial Password Verification Example
You want to confirm you know a password or secret phrase without revealing it.
Use a zero-knowledge proof:
You and the verifier settle on a mathematical conundrum or issue, such as figuring out a big number's components.
The puzzle or problem is then solved using the hidden knowledge that you have learned. You may, for instance, utilize your understanding of the password to determine the components of a particular number.
You provide your answer to the verifier, who can assess its accuracy without knowing anything about your private data.
You go through this process several times with various riddles or issues to persuade the verifier that you actually are aware of the secret knowledge.
You solved the mathematical puzzles or problems, proving to the verifier that you know the hidden information. The proof is zero-knowledge since the verifier only sees puzzle solutions, not the secret information.
In this scenario, the mathematical challenge or problem represents the secret, and solving it proves you know it. The evidence does not expose the secret, and the verifier just learns that you know it.
My simple example meets the zero-knowledge proof conditions:
Completeness: If you actually know the hidden information, you will be able to solve the mathematical puzzles or problems, hence the proof is conclusive.
Soundness: The proof is sound because the verifier can use a publicly known algorithm to confirm that your answer to the mathematical conundrum or difficulty is accurate.
Zero-knowledge: The proof is zero-knowledge because all the verifier learns is that you are aware of the confidential information. Beyond the fact that you are aware of it, the verifier does not learn anything about the secret information itself, such as the password or the factors of the number. As a result, the proof does not provide any new insights into the secret.
Explanation #2: Toss a coin.
One coin is biased to come up heads more often than tails, while the other is fair (i.e., comes up heads and tails with equal probability). You know which coin is which, but you want to show a friend you can tell them apart without telling them.
Use a zero-knowledge proof:
One of the two coins is chosen at random, and you secretly flip it more than once.
You show your pal the following series of coin flips without revealing which coin you actually flipped.
Next, as one of the two coins is flipped in front of you, your friend asks you to tell which one it is.
Then, without revealing which coin is which, you can use your understanding of the secret order of coin flips to determine which coin your friend flipped.
To persuade your friend that you can actually differentiate between the coins, you repeat this process multiple times using various secret coin-flipping sequences.
In this example, the series of coin flips represents the knowledge of biased and fair coins. You can prove you know which coin is which without revealing which is biased or fair by employing a different secret sequence of coin flips for each round.
The evidence is zero-knowledge since your friend does not learn anything about which coin is biased and which is fair other than that you can tell them differently. The proof does not indicate which coin you flipped or how many times you flipped it.
The coin-flipping example meets zero-knowledge proof requirements:
Completeness: If you actually know which coin is biased and which is fair, you should be able to distinguish between them based on the order of coin flips, and your friend should be persuaded that you can.
Soundness: Your friend may confirm that you are correctly recognizing the coins by flipping one of them in front of you and validating your answer, thus the proof is sound in that regard. Because of this, your acquaintance can be sure that you are not just speculating or picking a coin at random.
Zero-knowledge: The argument is that your friend has no idea which coin is biased and which is fair beyond your ability to distinguish between them. Your friend is not made aware of the coin you used to make your decision or the order in which you flipped the coins. Consequently, except from letting you know which coin is biased and which is fair, the proof does not give any additional information about the coins themselves.
Figure out the prime number in Example #3.
You want to prove to a friend that you know their product n=pq without revealing p and q. Zero-knowledge proof?
Use a variant of the RSA algorithm. Method:
You determine a new number s = r2 mod n by computing a random number r.
You email your friend s and a declaration that you are aware of the values of p and q necessary for n to equal pq.
A random number (either 0 or 1) is selected by your friend and sent to you.
You send your friend r as evidence that you are aware of the values of p and q if e=0. You calculate and communicate your friend's s/r if e=1.
Without knowing the values of p and q, your friend can confirm that you know p and q (in the case where e=0) or that s/r is a legitimate square root of s mod n (in the situation where e=1).
This is a zero-knowledge proof since your friend learns nothing about p and q other than their product is n and your ability to verify it without exposing any other information. You can prove that you know p and q by sending r or by computing s/r and sending that instead (if e=1), and your friend can verify that you know p and q or that s/r is a valid square root of s mod n without learning anything else about their values. This meets the conditions of completeness, soundness, and zero-knowledge.
Zero-knowledge proofs satisfy the following:
Completeness: The prover can demonstrate this to the verifier by computing q = n/p and sending both p and q to the verifier. The prover also knows a prime number p and a factorization of n as p*q.
Soundness: Since it is impossible to identify any pair of numbers that correctly factorize n without being aware of its prime factors, the prover is unable to demonstrate knowledge of any p and q that do not do so.
Zero knowledge: The prover only admits that they are aware of a prime number p and its associated factor q, which is already known to the verifier. This is the extent of their knowledge of the prime factors of n. As a result, the prover does not provide any new details regarding n's prime factors.
Types of Proofs of Zero Knowledge
Each zero-knowledge proof has pros and cons. Most zero-knowledge proofs are:
Interactive Zero Knowledge Proofs: The prover and the verifier work together to establish the proof in this sort of zero-knowledge proof. The verifier disputes the prover's assertions after receiving a sequence of messages from the prover. When the evidence has been established, the prover will employ these new problems to generate additional responses.
Non-Interactive Zero Knowledge Proofs: For this kind of zero-knowledge proof, the prover and verifier just need to exchange a single message. Without further interaction between the two parties, the proof is established.
A statistical zero-knowledge proof is one in which the conclusion is reached with a high degree of probability but not with certainty. This indicates that there is a remote possibility that the proof is false, but that this possibility is so remote as to be unimportant.
Succinct Non-Interactive Argument of Knowledge (SNARKs): SNARKs are an extremely effective and scalable form of zero-knowledge proof. They are utilized in many different applications, such as machine learning, blockchain technology, and more. Similar to other zero-knowledge proof techniques, SNARKs enable one party—the prover—to demonstrate to another—the verifier—that they are aware of a specific piece of information without disclosing any more information about that information.
The main characteristic of SNARKs is their succinctness, which refers to the fact that the size of the proof is substantially smaller than the amount of the original data being proved. Because to its high efficiency and scalability, SNARKs can be used in a wide range of applications, such as machine learning, blockchain technology, and more.
Uses for Zero Knowledge Proofs
ZKP applications include:
Verifying Identity ZKPs can be used to verify your identity without disclosing any personal information. This has uses in access control, digital signatures, and online authentication.
Proof of Ownership ZKPs can be used to demonstrate ownership of a certain asset without divulging any details about the asset itself. This has uses for protecting intellectual property, managing supply chains, and owning digital assets.
Financial Exchanges Without disclosing any details about the transaction itself, ZKPs can be used to validate financial transactions. Cryptocurrency, internet payments, and other digital financial transactions can all use this.
By enabling parties to make calculations on the data without disclosing the data itself, Data Privacy ZKPs can be used to preserve the privacy of sensitive data. Applications for this can be found in the financial, healthcare, and other sectors that handle sensitive data.
By enabling voters to confirm that their vote was counted without disclosing how they voted, elections ZKPs can be used to ensure the integrity of elections. This is applicable to electronic voting, including internet voting.
Cryptography Modern cryptography's ZKPs are a potent instrument that enable secure communication and authentication. This can be used for encrypted messaging and other purposes in the business sector as well as for military and intelligence operations.
Proofs of Zero Knowledge and Compliance
Kubernetes and regulatory compliance use ZKPs in many ways. Examples:
Security for Kubernetes ZKPs offer a mechanism to authenticate nodes without disclosing any sensitive information, enhancing the security of Kubernetes clusters. ZKPs, for instance, can be used to verify, without disclosing the specifics of the program, that the nodes in a Kubernetes cluster are running permitted software.
Compliance Inspection Without disclosing any sensitive information, ZKPs can be used to demonstrate compliance with rules like the GDPR, HIPAA, and PCI DSS. ZKPs, for instance, can be used to demonstrate that data has been encrypted and stored securely without divulging the specifics of the mechanism employed for either encryption or storage.
Access Management Without disclosing any private data, ZKPs can be used to offer safe access control to Kubernetes resources. ZKPs can be used, for instance, to demonstrate that a user has the necessary permissions to access a particular Kubernetes resource without disclosing the details of those permissions.
Safe Data Exchange Without disclosing any sensitive information, ZKPs can be used to securely transmit data between Kubernetes clusters or between several businesses. ZKPs, for instance, can be used to demonstrate the sharing of a specific piece of data between two parties without disclosing the details of the data itself.
Kubernetes deployments audited Without disclosing the specifics of the deployment or the data being processed, ZKPs can be used to demonstrate that Kubernetes deployments are working as planned. This can be helpful for auditing purposes and for ensuring that Kubernetes deployments are operating as planned.
ZKPs preserve data and maintain regulatory compliance by letting parties prove things without revealing sensitive information. ZKPs will be used more in Kubernetes as it grows.

Ben Carlson
3 years ago
Bear market duration and how to invest during one

Bear markets don't last forever, but that's hard to remember. Jamie Cullen's illustration
A bear market is a 20% decline from peak to trough in stock prices.
The S&P 500 was down 24% from its January highs at its low point this year. Bear market.
The U.S. stock market has had 13 bear markets since WWII (including the current one). Previous 12 bear markets averaged –32.7% losses. From peak to trough, the stock market averaged 12 months. The average time from bottom to peak was 21 months.
In the past seven decades, a bear market roundtrip to breakeven has averaged less than three years.
Long-term averages can vary widely, as with all historical market data. Investors can learn from past market crashes.
Historical bear markets offer lessons.
Bear market duration
A bear market can cost investors money and time. Most of the pain comes from stock market declines, but bear markets can be long.
Here are the longest U.S. stock bear markets since World war 2:
Stock market crashes can make it difficult to break even. After the 2008 financial crisis, the stock market took 4.5 years to recover. After the dotcom bubble burst, it took seven years to break even.
The longer you're underwater in the market, the more suffering you'll experience, according to research. Suffering can lead to selling at the wrong time.
Bear markets require patience because stocks can take a long time to recover.
Stock crash recovery
Bear markets can end quickly. The Corona Crash in early 2020 is an example.
The S&P 500 fell 34% in 23 trading sessions, the fastest bear market from a high in 90 years. The entire crash lasted one month. Stocks broke even six months after bottoming. Stocks rose 100% from those lows in 15 months.
Seven bear markets have lasted two years or less since 1945.
The 2020 recovery was an outlier, but four other bear markets have made investors whole within 18 months.
During a bear market, you don't know if it will end quickly or feel like death by a thousand cuts.
Recessions vs. bear markets
Many people believe the U.S. economy is in or heading for a recession.
I agree. Four-decade high inflation. Since 1945, inflation has exceeded 5% nine times. Each inflationary spike caused a recession. Only slowing economic demand seems to stop price spikes.
This could happen again. Stocks seem to be pricing in a recession.
Recessions almost always cause a bear market, but a bear market doesn't always equal a recession. In 1946, the stock market fell 27% without a recession in sight. Without an economic slowdown, the stock market fell 22% in 1966. Black Monday in 1987 was the most famous stock market crash without a recession. Stocks fell 30% in less than a week. Many believed the stock market signaled a depression. The crash caused no slowdown.
Economic cycles are hard to predict. Even Wall Street makes mistakes.
Bears vs. bulls
Bear markets for U.S. stocks always end. Every stock market crash in U.S. history has been followed by new all-time highs.
How should investors view the recession? Investing risk is subjective.
You don't have as long to wait out a bear market if you're retired or nearing retirement. Diversification and liquidity help investors with limited time or income. Cash and short-term bonds drag down long-term returns but can ensure short-term spending.
Young people with years or decades ahead of them should view this bear market as an opportunity. Stock market crashes are good for net savers in the future. They let you buy cheap stocks with high dividend yields.
You need discipline, patience, and planning to buy stocks when it doesn't feel right.
Bear markets aren't fun because no one likes seeing their portfolio fall. But stock market downturns are a feature, not a bug. If stocks never crashed, they wouldn't offer such great long-term returns.